
Phân loại các thuật toán
Có rất nhiều loại thuật toán về Machine Learning, thông thường chúng được phân ra làm các loại với tiêu chí như sau:
- Quá trình huấn luyện có cần sự giám sát của con người hay không?: Supervised (có giám sát), unsupervised (không giám sát), semisupervised (nửa giám sát), và Reinforcement Learning (học tăng cường)
- So sánh các điểm dữ liệu mới với các điểm dữ liệu cũ để đưa ra kết luận hoặc xây dựng các mẫu quy tắc cho dữ liệu huấn luyện rồi xây dựng các model để dự đoán giống như các scientist vẫn hay làm (instance-based và model-based learning)
Supervised/Unsupervised Learning
Thuật toán này thường được dùng trong các bài toán phân cụm/gán nhãn cho dữ liệu.
Supervised Learning
Dữ liệu đầu vào để đưa vào huấn luyện thuật toán gồm dữ liệu và nhãn (label) của dữ liệu
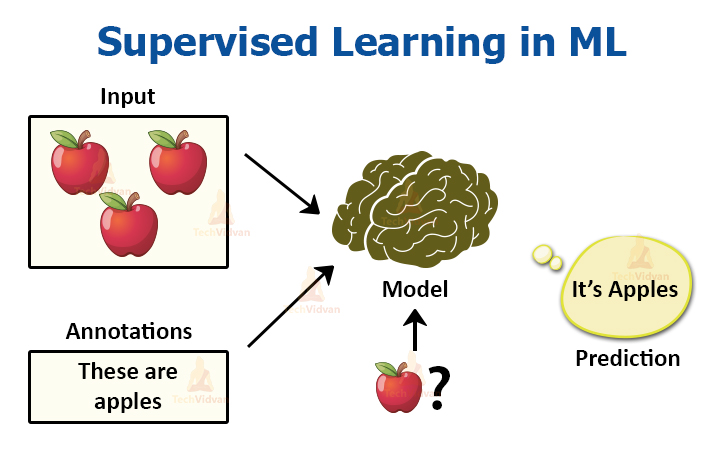 Ví dụ về Supervised learning
Ví dụ về Supervised learning
Một loại thuật toán của supervised learning là việc gán nhãn dữ liệu. Bộ lọc email là 1 ví dụ cho thuật toán này. Model được huấn luyện với rất nhiều mẫu email và mỗi email được gán nhãn (spam hoặc không spam). Và thuật toán cần phải học được cách phân loại khi cần xác định 1 email mới có phải là spam hay không.
Một loại nữa đó là dự đoán giá trị số đầu ra (output), ví dụ như giá xe ô tô với đầu vào (input) là các thuộc tính của chiếc xe đó(tuổi đời, số km đã chạy, thương hiệu…). Loại thuật toán này được gọi là Hồi quy (regression). Để huấn luyện chúng ta phải đưa đầu vào là rất nhiều thông tin về những chiếc xe với các thông số kèm theo giá của chúng)
Một số thuật toán hồi quy cũng có thể được sử dụng để phân loại và ngược lại. Ví dụ: Hồi quy logistic thường được sử dụng để phân loại, vì nó có thể xuất ra một giá trị tương ứng với xác suất thuộc về một lớp nhất định (ví dụ: 20% khả năng là spam).
Sau đây là 1 số thuật toán học giám sát mà mình sẽ đề cập dần trong blog:
- k-Nearest Neighbors
- Linear Regression
- Logistic Regression
- Support Vector Machines (SVMs)
- Decision Trees and Random Forests
- Neural networks
Unsupervised learning
Trong thuật toán học không giám sát, dữ liệu huấn luyện không được gán nhãn. Hệ thống sẽ học mà không cần ai dạy.
Sau đây là một vài thuật toán học không giám sát quan trọng nhất mà mình sẽ đề cập trong các phần tới:
Phân cụm
- k-Means
- Hierarchical Cluster Analysis (HCA)
- Expectation Maximization
Biểu diễn và giảm số chiều
- Principal Component Analysis (PCA)
- Kernel PCA— Locally-Linear Embedding (LLE)
- t-distributed Stochastic Neighbor Embedding (t-SNE)
Học từ luật kết hợp
- Apriori
- Eclat
Ví dụ: giả sử bạn có rất nhiều dữ liệu về khách truy cập blog của bạn. Bạn có thể muốn chạy một thuật toán phân cụm để cố gắng phát hiện các nhóm khách truy cập. Bạn không bao giờ biết khách truy cập thuộc về nhóm nào nhưng thuật toán học không giám sát sẽ tự động phân nhóm các khách truy cập.
Có thể nhận thấy rằng 40% khách truy cập của bạn là nam và thích công nghệ, thường đọc blog của bạn vào buổi tối, trong khi 20% là những người yêu thích , thường đọc vào cuối tuần, v.v. Nếu bạn sử dụng thuật toán phân cụm theo phân cấp, nó cũng có thể chia mỗi nhóm thành các nhóm nhỏ hơn. Điều này có thể giúp bạn nhắm mục tiêu bài viết của bạn.
Semi-Supervised Learning (Học bán giám sát)
Các bài toán khi chúng ta có một lượng lớn dữ liệu nhưng chỉ một phần trong chúng được gán nhãn được gọi là Semi-Supervised Learning. Những bài toán thuộc nhóm này nằm giữa hai nhóm được nêu bên trên.
Một ví dụ điển hình của nhóm này là chỉ có một phần ảnh hoặc văn bản được gán nhãn (ví dụ bức ảnh về người, động vật hoặc các văn bản khoa học, chính trị) và phần lớn các bức ảnh/văn bản khác chưa được gán nhãn được thu thập từ internet. Thực tế cho thấy rất nhiều các bài toán Machine Learning thuộc vào nhóm này vì việc thu thập dữ liệu có nhãn tốn rất nhiều thời gian và có chi phí cao. Rất nhiều loại dữ liệu thậm chí cần phải có chuyên gia mới gán nhãn được (ảnh y học chẳng hạn). Ngược lại, dữ liệu chưa có nhãn có thể được thu thập với chi phí thấp từ internet.
Học tăng cường (Reinforcement Learning)
Khác với học có giám sát, trong học tăng cường không có các cặp dữ liệu vào/kết quả đúng, các hành động gần tối ưu cũng không được đánh giá đúng sai một cách tường minh. Hơn nữa, ở đây hoạt động trực tuyến (on-line performance) được quan tâm, trong đó có việc tìm kiếm một sự cân bằng giữa khám phá (lãnh thổ chưa lập bản đồ) và khai thác (tri thức hiện có). Trong học tăng cường, sự được và mất giữa khám phá và khai thác đã được nghiên cứu chủ yếu qua bài toán multi-armed bandit.
Tóm lại
Có nhiều thuật toán học khác nhau và được phân loại dựa theo các tiêu chí khác nhau, các bạn có thể tự đưa ra một tiêu chí và phân loại theo cách của mình cũng không vấn đề gì :)) Mình chỉ tổng hợp lại 1 số cách phân loại mà mọi người hay dùng. Hi vọng qua bài viết này mọi người sẽ hiểu thêm về các loại thuật toán trong ML.