
Tăng cường dữ liệu (Data Augmentation) là một khái niệm khá phổ biến trong deep learning mà chắc hẳn ai đang nghiên cứu cũng đã từng nghe hoặc sử dụng đến. Nói đơn giản hơn, Data Augmentation là kỹ thuật tạo ra thêm dữ liệu để bổ sung cho tập dữ liệu để giúp mô hình khái quát tốt hơn. Các kỹ thuật data augmentation được sử dụng nhiều trong thị giác máy tính, thuật toán supervised learning… Tuy nhiên trong NLP thì cá nhân mình thấy ít được sử dụng và với Tiếng Việt thì chưa thấy bài viết nào đề cập đến.
Giới thiệu
“Deep learning is a data-hungry framework”. Tạm dịch câu này là Học sâu là 1 framework luôn “đói dữ liệu”. Câu này có ý nghĩa là dữ liệu là một phần quan trọng trong học sâu nói riêng và trong học máy nói chung. Và bởi vì deep learning là thuật toán dựa trên data (data-driven approach), và càng nhiều data thì càng dễ dẫn đến chất lượng các ứng dụng học máy được cải thiện.
Vậy nếu giờ chúng ta phải xử lý bài toán có giữ liệu giới hạn thì phải làm sao? Không đủ dữ liệu sẽ dẫn tới vấn đề như
- Thiếu tính generalization: Over-fitting hay như một kiểu học vẹt, Train thì chất lượng rõ cao còn test thì lẹt đẹt.
- Khó huấn luyện: Mạng DL nhạy cảm với giá trị khởi tạo, khó hội tụ
-
Chất lượng dự đoán sẽ không ổn định:
- Outlier - một số trường hợp kết quả sai khác rất nhiều,
- Nhiễu với đầu vào ảnh hưởng lớn tới chất lượng dự đoán
… vân vân và mây mây. [1]
Bài toán
Trong thị giác máy tính bạn có thể dễ dàng tìm được các kỹ thuật tăng cường dữ liệu, tuy nhiên trong xử lý ngôn ngữ tự nhiên thì kỹ thuật này còn gặp nhiều khó khăn do domain của các bài toán NLP là khác nhau.
Trong blog này mình sẽ bàn luận chủ yếu về kỹ thuật data augmentation trong NLP và cụ thể là bài toán phân lớp văn bản (text classification).
Giới thiệu về bài toán
Bài toán mình đưa ra được áp dụng trong hệ thống hỏi đáp sử dụng với chatbot. Đó là module xác định ý định câu hỏi của người dùng đặt câu hỏi cho chatbot. Về cơ bản việc xác định ý định của câu hỏi sẽ được chúng ta đưa về bài toán phân loại văn bản, với các ý định là các class (lớp) tương ứng.
Cụ thể hơn, mình đang thực hiện xây dựng hệ thống hỏi đáp dành cho sinh viên trường Đại học Xây dựng. Ý tưởng là sinh viên sẽ đặt câu hỏi cho hệ thống, sau đó hệ thống sẽ tìm ra những câu trả lời phù hợp bằng cách tìm kiếm câu hỏi trong tập dữ liệu câu hỏi - câu trả lời để xem câu hỏi đó gần với câu hỏi nào nhất để đưa ra câu trả lời tương ứng. Và để đưa ra được câu trả lời chính xác thì chúng ta cần phải xác định được ý định của câu hỏi mà người dùng muốn hỏi là gì. Và phần này sẽ tập trung chính vào kỹ thuật sinh câu hỏi tương ứng với ý định của người dùng để bổ sung thêm dữ liệu vào tập dữ liệu huấn luyện.
Tất cả các câu hỏi của sinh viên trong trường được chia ra thành các class như sau, mỗi class tương ứng với ý định hỏi của người dùng. Như vậy việc xác định ý định chính là việc phân lớp 1 câu hỏi thuộc vào class nào:
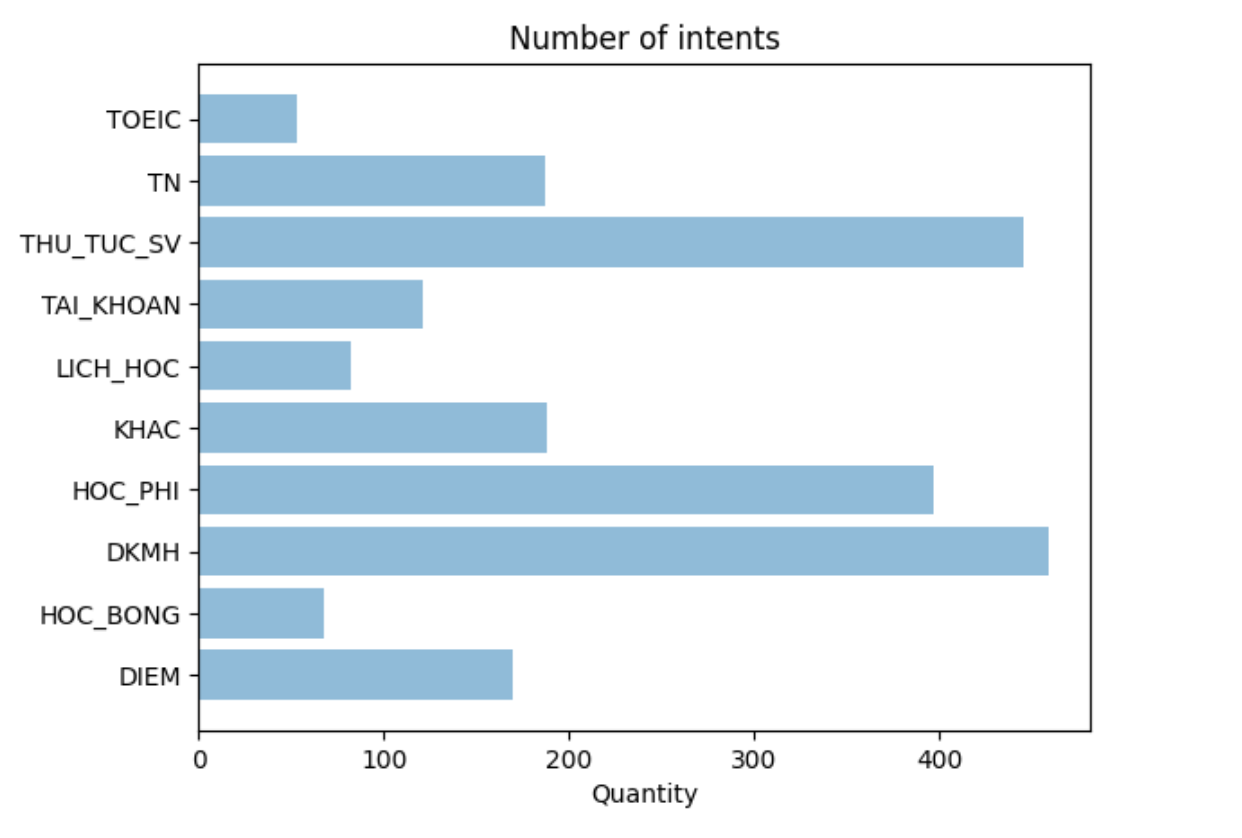 Số lượng các câu hỏi trong các class
Số lượng các câu hỏi trong các class
Như hình trên các bạn có thể thấy số lượng các câu hỏi trong các class là không đều nhau, các câu hỏi thuộc class TOEIC chỉ khoảng 50 câu hỏi, trong khi các câu hỏi trong class DKMH lại là gần 480 câu hỏi. Việc mất cân bằng dữ liệu này sẽ ảnh hưởng nhiều đến chất lượng của mô hình. Có nhiều phương pháp để xử lý mất cân bằng dữ liệu, tuy nhiên các phương pháp chủ yếu tập trung vào việc phân chia tập dữ liệu huấn luyện và kiểm tra chứ không tập trung vào việc bổ sung thêm dữ liệu. Việc bổ sung dữ liệu sẽ giúp cải thiện mô hình một cách tốt hơn.
Phương pháp thêm dữ liệu
Một số phương pháp thêm dữ liệu:
- Collect more data. Đúng nghĩa đen xì là lấy thêm dữ liệu. Trả tiền, lấy dữ liệu trên mạng, .v.v.
- Data synthesis: Tạo dữ liệu giả. Đối với một số bài toán dữ liệu có thể được mô phỏng qua computer graphic. Như ảnh depth, ảnh ở chiều góc nhìn khác nhau, .v.v.
- Data Augmentation. Là kỹ thuật đơn giản nhất bằng việc xử lý đơn giản dữ liệu sẵn có bằng các phép tuyến tính hay phi tuyến (như tạo dữ liệu qua mạng GAN)
Phương pháp 1 thì quá tốt nếu thực hiện được, tuy nhiên vì nhiều lý do và điều kiện ta không thể thu thập thêm được dữ liệu vì việc này tốn thời gian, công sức và cả tiền nữa.
Phương pháp số 2 thì khó có thể áp dụng được cho bài toán xử lý ngôn ngữ tự nhiên NLP.
Phương pháp số 3 sẽ phù hợp hơn trong bài toán này và mình sẽ đề cập trong phần tiếp theo.
BERT
BERT được coi là bước đột phá trong công nghệ xử lý ngôn ngữ tự nhiên của Google. Năm 2018 Google giới thiệu BERT, BERT là viết tắt của Bidirectional Encoder Representations from Transformers được hiểu là một mô hình học sẵn hay còn gọi là pre-train model, học ra các vector đại diện theo ngữ cảnh 2 chiều của từ, được sử dụng để transfer sang các bài toán khác trong lĩnh vực xử lý ngôn ngữ tự nhiên. BERT đã thành công trong việc cải thiện những công việc gần đây trong việc tìm ra đại diện của từ trong không gian số (không gian mà máy tính có thể hiểu được) thông qua ngữ cảnh của nó. [2]
Như chúng ta đã biết, xử lý ngôn ngữ tự nhiên luôn gặp phải vấn đề về thiếu hụt dữ liệu, hầu hết các tập dữ liệu chỉ đặc thù cho từng domain cụ thể. Để giải quyết thách thức này, các mô hình xử lý ngôn ngữ tự nhiên sử dụng một cơ chế tiền xử lý dữ liệu huấn luyện bằng việc transfer từ một mô hình chung được đào tạo từ một lượng lớn các dữ liệu không được gán nhãn. [2]
#BERT trong Tiếng Việt - phoBERT
Khi google đưa ra mã nguồn mở của BERT, có rất nhiều dự án dựa trên BERT được chia sẻ. Đối với Tiếng Việt chúng ta có phoBert do VinAI public.
PhoBert được huấn luyện dựa trên tập dữ liệu Tiếng Việt khá lớn nên khi sử dụng phoBERT nhìn chung cải thiện khá tốt các bài toán NLP với Tiếng Việt. Các bạn có thể sử dụng
Để sử dụng phoBERT, bạn cài đặt các gói sau:
1
2
!pip3 install fairseq
!pip3 install fastbpe
Download pretrained bert model
Đầu tiên chúng ta cần download toàn bộ pretrain của model bằng lệnh sau:
1
2
!wget https://public.vinai.io/PhoBERT_base_fairseq.tar.gz
!tar -xzvf PhoBERT_base_fairseq.tar.gz
Trong thư mục tải về sẽ có 3 file sau:
-
bpe.codes: BPE token dùng để mã hóa bằng bpe. -
dict.txt: Từ điển của tập dữ liệu dùng huấn luyện mô hình. -
model.pt: File pretrain chính của model.
Load model bằng python
1
2
3
4
# Load the model in fairseq
from fairseq.models.roberta import RobertaModel
phoBERT = RobertaModel.from_pretrained('PhoBERT_base_fairseq', checkpoint_file='model.pt')
phoBERT.eval() # disable dropout (or leave in train mode to finetune
Ở đây chúng ta sử dụng RobertaModel, đây là một mô hình dựa trên BERT nhưng có nhiều cải tiến và được đánh giá là tốt hơn so với BERT.
Fine-tune phoBERT
Mình sẽ tìm cách finetune lại model với dữ liệu huấn luyện của mình để phù hợp với bài toán mình cần thực hiện.
Trước tiên bạn cần download mã nguồn của fairseq:
1
2
!wget https://public.vinai.io/PhoBERT_large_fairseq.tar.gz
!tar -xzvf PhoBERT_large_fairseq.tar.gz
Sau đó switch vào thư mục vừa download
1
2
3
4
import os
os.chdir("fairseq")
!ls
Thực hiện cài đặt các gói và thư viện cần thiết:
1
!pip install --editable ./
Kết quả:
1
2
3
4
5
6
7
Installing collected packages: fairseq
Found existing installation: fairseq 0.10.2
Uninstalling fairseq-0.10.2:
Successfully uninstalled fairseq-0.10.2
Running setup.py develop for fairseq
Successfully installed fairseq
Sau đây là các bước thực hiện finetune phoBERT
Dữ liệu huấn luyện
Dữ liệu trong bài toán này của mình là các câu hỏi trong tập dữ liệu câu hỏi của sinh viên trường Đại học Xây dựng mà mình đang xây dựng hệ thống hỏi đáp tự động. Mỗi câu hỏi sẽ được gán nhãn tương ứng với ý định của câu hỏi. Mình sẽ sử dụng nhãn này để sinh thêm câu hỏi tương ứng với nhãn mong muốn.
Ví dụ một câu hỏi như sau: “Cô ơi cho e hỏi về việc đăng kí và hủy môn học , môn e đăng kí vừa mới có điểm và e muốn hủy đăng kí môn đó vào kì 3 có đc không ạ” có nhãn là Đăng ký môn học vì người hỏi có ý định hỏi về việc đăng ký môn học.
Dữ liệu huấn luyện sẽ cần phải được encode về dạng bpe (Byte Pair Encoding) trước khi đưa vào mô hình.
Tìm hiểu về mã hóa BPE
BPE (Byte Pair Encoding) là một kỹ thuật nén từ cơ bản giúp chúng ta index được toàn bộ các từ kể cả trường hợp từ mở (không xuất hiện trong từ điển) nhờ mã hóa các từ bằng chuỗi các từ phụ (subwords). Nguyên lý hoạt động của BPE dựa trên phân tích trực quan rằng hầu hết các từ đều có thể phân tích thành các thành phần con.
Chẳng hạn như từ: low, lower, lowest đều là hợp thành bởi low và những đuôi phụ er, est. Những đuôi này rất thường xuyên xuất hiện ở các từ. Như vậy khi biểu diễn từ lower chúng ta có thể mã hóa chúng thành hai thành phần từ phụ (subwords) tách biệt là low và er. Theo cách biểu diễn này sẽ không phát sinh thêm một index mới cho từ lower và đồng thời tìm được mối liên hệ giữa lower, lowest và low nhờ có chung thành phần từ phụ là low.
Phương pháp BPE sẽ thống kê tần suất xuất hiện của các từ phụ cùng nhau và tìm cách gộp chúng lại nếu tần suất xuất hiện của chúng là lớn nhất. Cứ tiếp tục quá trình gộp từ phụ cho tới khi không tồn tại các subword để gộp nữa, ta sẽ thu được tập subwords cho toàn bộ bộ văn bản mà mọi từ đều có thể biểu diễn được thông qua subwords.
Code của thuật toán BPE đã được tác giả chia sẻ tại subword-nmt.
Qúa trình này gồm các bước như sau:
Bước 1: Khởi tạo từ điển (vocabulary).
Bước 2: Biểu diễn mỗi từ trong bộ văn bản bằng kết hợp của các ký tự với token <\w> ở cuối cùng đánh dấu kết thúc một từ (lý do thêm token sẽ được giải thích bên dưới).
Bước 3: Thống kê tần suất xuất hiện theo cặp của toàn bộ token trong từ điển.
Bước 4: Gộp các cặp có tần suất xuất hiện lớn nhất để tạo thành một n-gram theo level character mới cho từ điển.
Bước 5: Lặp lại bước 3 và bước 4 cho tới khi số bước triển khai merge đạt đỉnh hoặc kích thước kỳ vọng của từ điển đạt được.
(theo https://phamdinhkhanh.github.io/2020/06/04/PhoBERT_Fairseq.html)
BPE tokenize trong BERT
Để thực hiện tokenize, chúng ta làm như sau:
1
2
3
4
5
6
7
8
9
10
11
12
13
from fairseq.data.encoders.fastbpe import fastBPE
# Khởi tạo Byte Pair Encoding cho PhoBERT
class BPE():
bpe_codes = 'PhoBERT_base_fairseq/bpe.codes'
args = BPE()
phoBERT.bpe = fastBPE(args) #Incorporate the BPE encoder into PhoBERT
tokens = phoBERT.encode('Hello world!')
print('tokens list : ', tokens)
# Decode ngược lại thành câu từ chuỗi index token
phoBERT.decode(tokens) # 'Hello world!'
Kết quả
1
tokens list : tensor([ 0, 11623, 31433, 1232, 2])
1
Hello world!
Các bước thực hiện
Khai báo các hàm tiền xử lý văn bản tiếng việt
Chúng ta sẽ sử dụng thư viện vncorenlp để tiến hành tách từ tiếng việt và sử dụng từ điển các từ dừng để loại bỏ các stopword.
Download thư viện tách từ
1
2
3
4
5
6
7
!mkdir -p vncorenlp/models/wordsegmenter
!wget https://raw.githubusercontent.com/vncorenlp/VnCoreNLP/master/VnCoreNLP-1.1.1.jar
!wget https://raw.githubusercontent.com/vncorenlp/VnCoreNLP/master/models/wordsegmenter/vi-vocab
!wget https://raw.githubusercontent.com/vncorenlp/VnCoreNLP/master/models/wordsegmenter/wordsegmenter.rdr
!mv VnCoreNLP-1.1.1.jar vncorenlp/
!mv vi-vocab vncorenlp/models/wordsegmenter/
!mv wordsegmenter.rdr vncorenlp/models/wordsegmenter/
Khai báo thư viện tách từ
1
2
3
4
5
6
7
8
9
10
11
filename = '/đường_dẫn/đến/stopwords.csv'
data = pd.read_csv(filename, sep="\t", encoding='utf-8')
list_stopwords = data['stopwords']
def remove_stopword(text):
pre_text = []
words = text.split()
for word in words:
if word not in list_stopwords:
pre_text.append(word)
text2 = ' '.join(pre_text)
return text2
Các bạn thay filename bằng tên đường dẫn file chứa các stopword.
Tiền xử lý văn bản
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
import string
import re
def clean_text(text):
text = re.sub('<.*?>', '', text).strip()
text = re.sub('(\s)+', r'\1', text)
return text
def remove_numbers(text_in):
for ele in text_in.split():
if ele.isdigit():
text_in = text_in.replace(ele, "@")
for character in text_in:
if character.isdigit():
text_in = text_in.replace(character, "@")
return text_in
def remove_special_characters(text):
chars = re.escape(string.punctuation)
return re.sub(r'['+chars+']', '', text)
def word_segment(sent):
sent = " ".join(rdrsegmenter.tokenize(sent.replace("\n", " ").lower())[0])
return sent
def preprocess(text_in):
text = clean_text(text_in)
text = remove_special_characters(text)
text = remove_numbers(text)
text = word_segment(text)
return text
Đọc dữ liệu:
Sau khi khai báo các hàm tiền xử lý, chúng ta sẽ tiến hành đọc dữ liệu từ file:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
import json
qa_data_path = '/content/drive/MyDrive/NUCE/NLP/QA/intent_db_v2.json'
def read_data(path):
traindata = []
with open(qa_data_path) as json_file:
qa_data = json.load(json_file)
for question in qa_data:
if 'content' in question :
content = preprocess(question['content'])
traindata.append(content.split())
print("Dataset loaded")
return qa_data
train_data, qa_data = read_data(wiki_data_path)
Chuẩn hóa dữ liệu
Để tạo ra các câu với class tương ứng, dữ liệu huấn luyện sẽ có dạng như sau:
<s> CLASS_NAME </s> content </s>
Lý do vì sao sử dụng phương pháp này, các bạn có thể đọc thêm paper CG-BERT: Conditional Text Generation with BERT for Generalized Few-shot Intent Detection:
1
2
3
4
5
6
7
import json
sents_output = []
intents_output = []
for question in qa_data:
if 'content' in question and 'intent' in question:
sents_output.append("<s> " + question['intent'] + " </s> " + preprocess(question['content']).replace("\n", " ") + " </s>")
intents_output.append(question['intent'])
1
sents_output[:10]
Kết quả sau khi chuẩn hóa sẽ là:
1
2
3
4
5
6
7
8
9
10
['<s> DIEM </s> cho em hỏi em có_thể chuyển_đổi kết_quả @ môn_học cùng tên nhưng khác mã được không ạ </s>',
'<s> DIEM </s> em mới làm đơn phúc_khảo gần đây ạ mà @ @ ngày rồi thấy mãi điểm chưa thay_đổi em có_thể xin phép đc xem bài thi của mình đc k ạ nếu em thực_sự sai em chỉ muốn xem_lại bài thi của mình </s>',
'<s> DIEM </s> cho em hỏi là làm_sao để biết kết_quả điểm phúc_khảo môn_học sau khi đã làm đơn phúc_khảo ạ </s>',
'<s> DIEM </s> thưa thầy muốn phúc_khảo điểm môn_học thì làm thế_nào ạ </s>',
'<s> DIEM </s> thầy_cô cho em hỏi là còn thời_gian phúc_tra điểm của kì học vừa_rồi không ạ vì dịch_bệnh không lên trường được nên em đã không phúc_tra được bài ạ </s>',
'<s> DIEM </s> cho em hỏi là muốn phúc_tra điểm thì làm thế_nào ạ </s>',
'<s> DIEM </s> cho em hỏi là thời_hạn phúc_khảo môn_học là bao_giờ ạ em cần làm đơn hay liên_hệ với ai để tiến_hành phúc_tra được ạ </s>',
'<s> DIEM </s> mong thầy_cô xem giúp e điểm trên trang đao tạo với ạ hiện_tại điểm đồ_án tốt_nghiệp của e đã được cập_nhật lên nhưng có_lẽ do lỗi mà chưa được cộng tổng điểm trung_bình tích_luỹ và số tín_chỉ của đồ_án tốt_nghiệp </s>',
'<s> DIEM </s> em có thắc_mắc muốn hỏi là @ tín_đồ án tốt_nghiệp đatn có tính vào số tín_chỉ tích_luỹ hay không\xa0lí do vì em thấy trên trang đào_tạo sau khi đã up điểm đatn của em lên lại không thấy tính @ tín_chỉ này vào số tính chỉ tích_luỹ ảnh chụp kèm theo là điểm của em </s>',
'<s> DIEM </s> dạ em chào thầy_cô thưa thầy_cô là điểm của em trên trang đào_tạo thầy vào điểm sai cho em và em đã hỏi thầy thầy có nói đã sửa lại điểm thế nên cho em hỏi bao_giờ đào_tạo cập_nhật lại điểm ạ e xin cảm_ơn thầy_cô ạ </s>']
Ở đây mình sử dụng token <s> như là token bắt đầu của câu, </s> là token phân cách câu.
Phân chia dữ liệu huấn luyện
Mình tiến hành phân chia dữ liệu thành 3 tập train, test và valid. Vì dữ liệu hơi ít nên mình sẽ để tập test và valid mỗi tập 50 điểm dữ liệu
1
2
3
4
5
6
7
import random
random.shuffle(sents_output)
valid_data = sents_output[:50]
test_data = sents_output[50:100]
train_data = sents_output[100:]
Mã hóa dữ liệu huấn luyện theo bpe
Dữ liệu huấn luyện cần được mã hóa thành các token bpe để có thể sử dụng cho các language model. Nếu bạn nào làm nhiều với NLP chắc hẳn đã quen với phương pháp này.
1
2
3
4
5
6
7
8
9
10
11
12
def encode_bpe(data, name, target_dir):
f = open(target_dir + "finetune." + name + ".bpe", "w")
for line in data:
bpe_enc = ""
tokens = phoBERT.encode(line)
for token in tokens:
bpe_enc = bpe_enc + str(token.item()) + " "
bpe_enc = bpe_enc + "\n"
f.write(bpe_enc)
f.close()
Sau khi mã hóa bpe, dữ liệu sẽ được lưu vào thư mục được chỉ định trong target_dir
1
2
3
4
save_path = "fintune_data"
encode_bpe(valid_data, "valid", save_path)
encode_bpe(test_data, "test", save_path)
encode_bpe(train_data, "train", save_path)
Đưa dữ liệu vào pha tiền xử lý để tạo đầu vào cho BERT
Ở đây chúng ta sẽ thực hiện thông qua thư viện qua command line như sau:
(các bạn nhớ thay /path/to/save_path thành đường dẫn lưu các file bpe trong bước trên)
1
! fairseq-preprocess --only-source --srcdict /path/to/save_path --workers 60
Bước này xử lý khá nhanh, chỉ vài giây là xong do tập dữ liệu của mình hơi ít. Sau khi chạy xong, dữ liệu sẽ được lưu vào thư mục
1
2
3
4
5
6
7
8
2021-05-08 15:37:31 | INFO | fairseq_cli.preprocess | Namespace(align_suffix=None, alignfile=None, all_gather_list_size=16384, azureml_logging=False, bf16=False, bpe=None, cpu=False, criterion='cross_entropy', dataset_impl='mmap', destdir='/content/drive/MyDrive/NUCE/NLP/QA/BERT/fairseq/data-bin/finetune_data', empty_cache_freq=0, fp16=False, fp16_init_scale=128, fp16_no_flatten_grads=False, fp16_scale_tolerance=0.0, fp16_scale_window=None, joined_dictionary=False, log_file=None, log_format=None, log_interval=100, lr_scheduler='fixed', memory_efficient_bf16=False, memory_efficient_fp16=False, min_loss_scale=0.0001, model_parallel_size=1, no_progress_bar=False, nwordssrc=-1, nwordstgt=-1, only_source=True, optimizer=None, padding_factor=8, plasma_path='/tmp/plasma', profile=False, quantization_config_path=None, reset_logging=False, scoring='bleu', seed=1, source_lang=None, srcdict='/content/drive/MyDrive/NUCE/NLP/QA/BERT/fairseq/PhoBERT_base_fairseq/dict.txt', suppress_crashes=False, target_lang=None, task='translation', tensorboard_logdir=None, testpref='/content/drive/MyDrive/NUCE/NLP/QA/BERT/fairseq/fintune_data/finetune.test.bpe', tgtdict=None, threshold_loss_scale=None, thresholdsrc=0, thresholdtgt=0, tokenizer=None, tpu=False, trainpref='/content/drive/MyDrive/NUCE/NLP/QA/BERT/fairseq/fintune_data/finetune.train.bpe', use_plasma_view=False, user_dir=None, validpref='/content/drive/MyDrive/NUCE/NLP/QA/BERT/fairseq/fintune_data/finetune.valid.bpe', wandb_project=None, workers=60)
2021-05-08 15:37:32 | INFO | fairseq_cli.preprocess | [None] Dictionary: 64000 types
2021-05-08 15:37:40 | INFO | fairseq_cli.preprocess | [None] /content/drive/MyDrive/NUCE/NLP/QA/BERT/fairseq/fintune_data/finetune.train.bpe: 2769 sents, 173535 tokens, 54.6% replaced by <unk>
2021-05-08 15:37:40 | INFO | fairseq_cli.preprocess | [None] Dictionary: 64000 types
2021-05-08 15:37:45 | INFO | fairseq_cli.preprocess | [None] /content/drive/MyDrive/NUCE/NLP/QA/BERT/fairseq/fintune_data/finetune.valid.bpe: 50 sents, 2951 tokens, 58.1% replaced by <unk>
2021-05-08 15:37:45 | INFO | fairseq_cli.preprocess | [None] Dictionary: 64000 types
2021-05-08 15:37:51 | INFO | fairseq_cli.preprocess | [None] /content/drive/MyDrive/NUCE/NLP/QA/BERT/fairseq/fintune_data/finetune.test.bpe: 50 sents, 3150 tokens, 53.1% replaced by <unk>
2021-05-08 15:37:51 | INFO | fairseq_cli.preprocess | Wrote preprocessed data to /content/drive/MyDrive/NUCE/NLP/QA/BERT/fairseq/data-bin/finetune_data
Mã hóa dataset thành file binary để huấn luyện model
Sau khi thực hiện preprocess, chúng ta cần chuyển data sang dạng binary theo yêu cầu của thư viện:
Trong bước này sẽ yêu cầu các bạn cung cấp file từ điển dict.txt được cho kèm theo phoBERT
1
! fairseq-preprocess --only-source --srcdict PhoBERT_base_fairseq/dict.txt --trainpref data-bin/fintune_data/finetune.train.bpe --validpref finetune.valid.bpe --testpref data-bin/finetune_data/finetune.test.bpe --workers 60
Sau khi xây dựng được tập dữ liệu huấn luyện, bước cuối cùng đó là thực hiện fine-tune thôi nào.
Tiến hành fine-tune
Chúng ta chạy lệnh sau:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
!fairseq-train --fp16 data-bin/finetune_data \
--task masked_lm --lr 2e-05 --criterion masked_lm \
--arch roberta_base --sample-break-mode complete \
--tokens-per-sample 256 --optimizer adam --adam-betas '(0.9,0.98)' \
--adam-eps 1e-6 --clip-norm 0.0 \
--lr-scheduler polynomial_decay \
--warmup-updates 10000 --total-num-update 12000 \
--dropout 0.1 --attention-dropout 0.1 --weight-decay 0.01 \
--batch-size 20 --update-freq 1 --log-format simple \
--log-interval 1 --reset-optimizer --reset-dataloader \
--reset-meters --sample-break-mode complete \
--restore-file PhoBERT_base_fairseq/model.pt \
--skip-invalid-size-inputs-valid-test \
--max-epoch 500 --no-epoch-checkpoints \
--no-last-checkpoints --no-save-optimizer-state
Mình sẽ huấn luyện thông qua 500 epochs, có sử dụng learning rate scheduler và khởi tạo ban đầu lr lớn 2e-05.
Trong câu lệnh trên chúng ta sẽ đưa vào pretrain của phoBERT bởi tham số --restore-file
Trong quá trình huấn luyện mình sẽ lưu lại các checkpoint có loss thấp nhất để sử dụng về sau. Sau khi huấn luyện, kết quả tốt nhất của mô hình sẽ được lưu vào file `checkpoint_best.pt’
Quá trình huấn luyện khá lâu, mình khuyên các bạn nếu máy tính không có GPU thì nên sử dụng google colab có GPU để đỡ mất công chờ đợi.
Sinh văn bản bằng phoBERT đã fine-tune
Trong bài toán này chúng ta sẽ sinh ra các câu mới bằng cách điền các từ hợp lý vào các vị trí còn trống của câu.
Mô hình BERT tạo ra các biểu diễn từ từ quá trình ẩn các vị trí token một cách ngẫu nhiên trong câu input và dự báo chính chính từ đó ở output dựa trên bối cảnh là các từ xung quanh.
Như vậy khi đã biết các từ xung quanh, chúng ta hoàn toàn có thể dự báo được từ phù hợp nhất với vị trí đã được masking.
Ý tưởng của việc sinh văn bản đó là mình sẽ tiến hành che lần lượt các từ trong câu và tìm ra các từ bị che, sau đó ghép lại các tử bị che thành câu mới.
Các bước thực hiện như sau:
Load lại model với weight mới
1
2
3
4
5
6
7
8
9
10
11
# Load the model in fairseq
from fairseq.data.encoders.fastbpe import fastBPE
from fairseq.models.roberta import RobertaModel
phoBERT = RobertaModel.from_pretrained('/path/to/checkpoints', checkpoint_file="checkpoint_best.pt")
# Khởi tạo Byte Pair Encoding cho PhoBERT
class BPE():
bpe_codes = '/content/drive/MyDrive/NUCE/NLP/QA/BERT/fairseq/checkpoints/bpe.codes'
args = BPE()
phoBERT.bpe = fastBPE(args) #Incorporate the BPE encoder into PhoBERT
Thực hiện sinh văn bản mới
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
import random
import re
seed = "Cho em hỏi bao giờ thì có bằng tốt nghiệp ạ"
intent = "TN"
words = preprocess(seed).split()
seed = " ".join(words)
gen_sentence = []
for i in range(len(words)):
tmp = words[i]
words[i] = "<mask>"
mask = "<s>'+intent+'</s> " + ' '.join(words) + "</s>"
print(mask)
topk_filled_outputs = phoBERT.fill_mask(mask , topk=1)
words[i] = tmp
gen_sentence.append(topk_filled_outputs[0][2])
print(gen_sentence)
Kết quả in ra sẽ là:
1
Xin tôi hỏi khi_nào sẽ có giấy_chứng_nhận tốt_nghiệp
Như vậy là câu được sinh ra khá là giống với câu seed, ngoài ra <mask> thay vì dịch từ trái qua phải, các bạn cũng có thể thử dịch từ phải qua trái.
Tổng kết
Như vậy trong bài này mình đã hướng dẫn các bạn cách finetune lại model phoBERT và thực hiện dùng model sau khi fine-tune để sinh văn bản mới. Kỹ thuật này có thể được sử dụng trong việc tạo thêm dữ liệu trong các bài toán xử lý ngôn ngữ tự nhiên để tăng thêm độ chính xác cho mô hình.
Hi vọng bài này giúp ích được cho mọi người!
Tài liệu tham khảo
-
https://arxiv.org/pdf/2004.01881.pdf
-
https://phamdinhkhanh.github.io/2020/06/04/PhoBERT_Fairseq.html
-
https://viblo.asia/p/bert-roberta-phobert-bertweet-ung-dung-state-of-the-art-pre-trained-model-cho-bai-toan-phan-loai-van-ban-4P856PEWZY3
-
https://medium.com/intel-student-ambassadors/natural-language-generation-using-bert-df6d863c3f52