
Phân đa lớp là những bài toán mà mô hình dự đoán trong đó các đầu vào được chỉ định là một trong nhiều hơn hai lớp.
Mô hình dự đoán một giá trị số nguyên, trong đó mỗi lớp được gán một giá trị số nguyên duy nhất từ 0 đến (num_classes - 1). Bài toán thường được thực hiện như là dự đoán xác suất của điểm dữ liệu thuộc về một lớp nào đó đã biết. num_classes là số class
Trong phần này, chúng ta sẽ khảo sát các hàm mất mát thích hợp cho các mô hình phân đa lớp.
Khởi tạo dữ liệu
Mình sẽ sử dụng bài toán blobs (các đốm màu) làm cơ sở để thử nghiệm các hàm mất mát. Hàm make_blobs () được cung cấp bởi thư viện scikit-learning cung cấp để tạo các điểm dữ liệu và các lớp tương ứng với điểm dữ liệu đó. Mình sẽ sử dụng hàm này để tạo ra 1.000 điểm dữ liệu cho bài toán phân loại 3 lớp với 2 biến đầu vào. Trình tạo số giả ngẫu nhiên sẽ được tạo ra để 1.000 ví dụ giống nhau được tạo ra mỗi khi chạy. (random_state)
1
2
# generate dataset
X, y = make_blobs(n_samples=1000, centers=3, n_features=2, cluster_std=2, random_state=2)
Hai biến đầu vào là x và y tương ứng với các điểm trong không gian 2 chiều.
Code dưới đây tạo ra một biểu đồ thể hiện sự phân tán của toàn bộ tập dữ liệu, các điểm được tô màu theo lớp tương ứng.
1
2
3
4
5
6
7
8
9
10
11
# scatter plot of blobs dataset
from sklearn.datasets import make_blobs
from numpy import where
from matplotlib import pyplot
# generate dataset
X, y = make_blobs(n_samples=1000, centers=3, n_features=2, cluster_std=2, random_state=2)
# select indices of points with each class label
for i in range(3):
samples_ix = where(y == i)
pyplot.scatter(X[samples_ix, 0], X[samples_ix, 1])
pyplot.show()
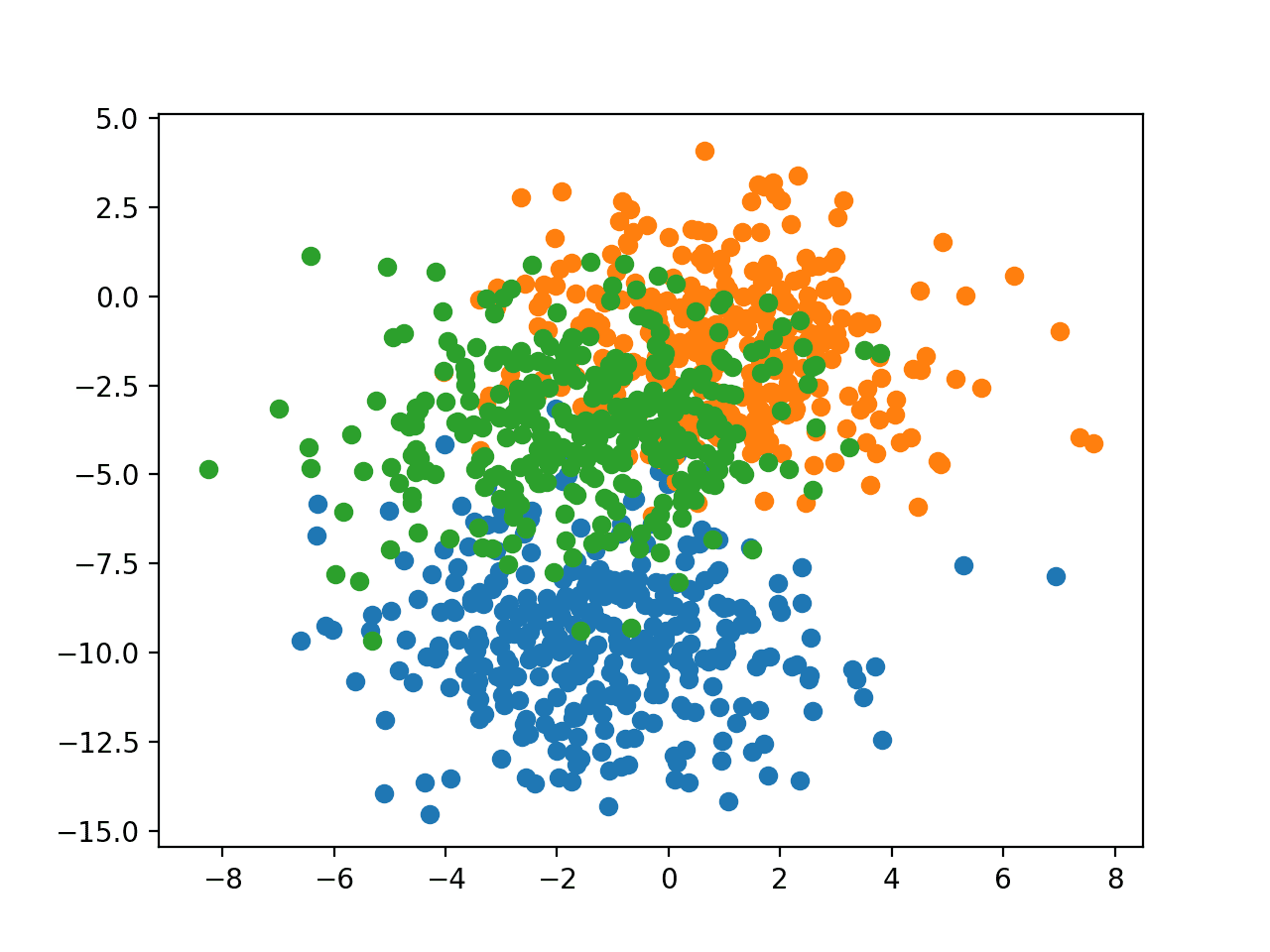 Dữ liệu cho bài toán phân đa lớp
Dữ liệu cho bài toán phân đa lớp
Các điểm dữ liệu sẽ không rescale chúng trong trường hợp này.
Phân chia dữ liệu train-test
1
2
3
4
# phân chia dữ liệu train-test
n_train = 500
trainX, testX = X[:n_train, :], X[n_train:, :]
trainy, testy = y[:n_train], y[n_train:]
Chuẩn bị mô hình
Chúng ta có thể sử dụng một mô hình MLP đơn giản để giải quyết bài toán này. Bài toán sẽ gồm đầu vào với 2 features, một lớp ẩn với 50 nút. Hàm kích hoạt tuyến tính và layer đầu ra mình sẽ lựa chọn theo mỗi hàm mất mát sẽ sử dụng.
1
2
3
4
# define model
model = Sequential()
model.add(Dense(50, input_dim=2, activation='relu', kernel_initializer='he_uniform'))
model.add(Dense(..., activation='...'))
Mô hình sẽ được fit bằng thuật toán SGD với learning rate là 0.01 và momentum là 0.9
1
2
opt = SGD(lr=0.01, momentum=0.9)
model.compile(loss='...', optimizer=opt, metrics=['accuracy'])
Mình sẽ huấn luyện mô hình với 100 epochs sau đó đánh giá mô hình với loss và độ chính xác (accuracy) ở mỗi epoch. Sau đó mình sẽ vẽ learning curves.
1
2
# fit model
history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=200, verbose=0)
Sau khi đã định nghĩa xong mô hình, bây giờ mình sẽ tiến hành thử nghiệm các hàm lỗi khác nhau và so sánh kết quả giữa các hàm loss để đưa ra nhận xét cho mỗi phương pháp.
Multi-Class Cross-Entropy Loss
Cross-entropy được sử dụng mặc định cho các bài toán phân đa lớp. Trong bài toán phân đa lớp, mục đích của mô hình là dự đoán xác suất của một điểm dữ liệu rơi vào class (lớp) nào trong số các class {0, 1, 3, …, n}, mỗi class tương ứng với một số nguyên
Về mặt toán học, hàm cross-entropy loss được ưu tiên sử dụng. Đây là hàm đánh giá sử dụng đầu tiên, và ta chỉ thay đổi hàm này nếu có lý do nào khác đặc biệt. y đổi nếu bạn có lý do chính đáng.
Nhắc lại bài trước, cross-entropy tính khoảng cách giữa 2 phân bố xác suất.
\[H(\mathbf{p}, \mathbf{q}) = \mathbf{E_p}[-\log \mathbf{q}]\]Với p và q là rời rạc (như y - nhãn thật sự và y^ - nhãn dự đoán ) trong bài toán của chúng ta), công thức này được viết dưới dạng:
\[H(\mathbf{p}, \mathbf{q}) =-\sum_{i=1}^C p_i \log q_i ~~~ (1)\]Trong đó C là số lượng các class cần phân lớp, trong bài toán binary classification thì C = 2.
Cross-entropy được cung cấp trong Keras bằng cách thiết lập tham số loss=‘categorical_crossentropy‘ khi compile mô hình.
1
model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy'])
Hàm yêu cầu lớp đầu ra được thiết lập với n node (một nút cho mỗi class), trong trường hợp này là 3 node và mình sử dụng hàm kích hoạt ‘softmax‘ để dự đoán xác suất cho mỗi lớp.
1
model.add(Dense(3, activation='softmax'))
Như vậy biến đích y phải dưới dạng one-hot encoding. Trong đó vị trí của số 1 trong vector sau khi biến đổi tương ứng với class của input. Ta thực hiện đưa đầu ra y thành dạng one-hot bằng hàm Keras.to_categorical()
1
2
# one hot encode output variable
y = to_categorical(y)
Code đầy đủ sử dụng hàm loss Cross-entropy được trình bày dưới đây:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
# mlp for the blobs multi-class classification problem with cross-entropy loss
from sklearn.datasets import make_blobs
from keras.layers import Dense
from keras.models import Sequential
from keras.optimizers import SGD
from keras.utils import to_categorical
from matplotlib import pyplot
# Khởi tạo dữ liệu 2 chiều cho bài toán phân đa lớp
X, y = make_blobs(n_samples=1000, centers=3, n_features=2, cluster_std=2, random_state=2)
# biến đổi đầu ra thành dạng one-hot encoding
y = to_categorical(y)
# split into train and test
n_train = 500
trainX, testX = X[:n_train, :], X[n_train:, :]
trainy, testy = y[:n_train], y[n_train:]
# định nghĩa mô hình
model = Sequential()
model.add(Dense(50, input_dim=2, activation='relu', kernel_initializer='he_uniform'))
model.add(Dense(3, activation='softmax'))
# compile mô hình
opt = SGD(lr=0.01, momentum=0.9)
model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy'])
# huấn luyện mô hình
history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=100, verbose=0)
# Đánh giá mô hình
_, train_acc = model.evaluate(trainX, trainy, verbose=0)
_, test_acc = model.evaluate(testX, testy, verbose=0)
print('Train: %.3f, Test: %.3f' % (train_acc, test_acc))
# vẽ đồ thị thể hiện giá trị loss trong quá trình huấn luyện
pyplot.subplot(211)
pyplot.title('Loss')
pyplot.plot(history.history['loss'], label='train')
pyplot.plot(history.history['val_loss'], label='test')
pyplot.legend()
# vẽ đồ thị thể hiện độ chính xác trong quá trình huấn luyện
pyplot.subplot(212)
pyplot.title('Accuracy')
pyplot.plot(history.history['accuracy'], label='train')
pyplot.plot(history.history['val_accuracy'], label='test')
pyplot.legend()
pyplot.show()
Sau khi chạy, kết quả sẽ in ra độ chính xác trên tập train và tập test
Chú ý khi chạy, kết quả có thể khác nhau do thuật toán khởi tạo ngẫu nhiên. Chúng ta nên chạy nhiều lần và lấy giá trị trung bình
Kết quả in ra sẽ là:
1
Train: 0.840, Test: 0.822
Trong trường hợp này chúng ta có thể thấy mô hình đạt độ chính xác khá tốt, 84% trên tập dữ liệu huấn luyện và 82% trên tập test.
Biểu đồ đường thể hiện giá trị cross-entropy trong quá trình huấn luyện của tập train (màu xanh) và tập test (màu cam)
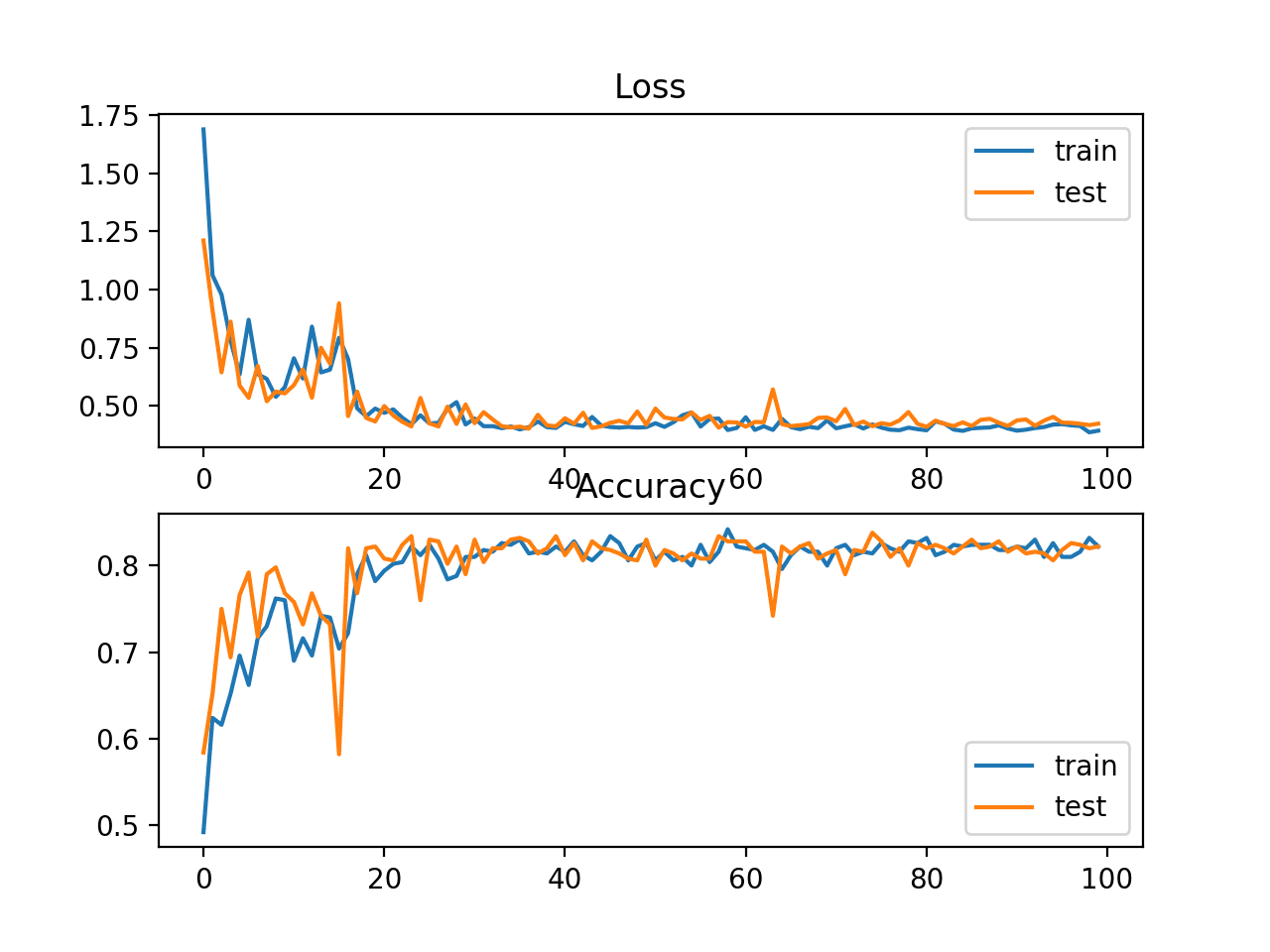 Đồ thị đường của hàm mất mát Cross Entropy và độ chính xác
Đồ thị đường của hàm mất mát Cross Entropy và độ chính xác
Trong trường hợp này, biểu đồ cho thấy mô hình có vẻ như đã hội tụ. Các đồ thị đường cho cả cross-entropy và độ chính xác đều cho thấy sự hội tụ tốt, mặc dù hơi nhấp nhô. Mô hình có vẻ tốt, không bị underfit hay overfit. Còn để biểu đồ mượt hơn, chúng ta có thể điều chỉnh batch size hoặc learning rate.
Sparse Multiclass Cross-Entropy Loss
Khi sử dụng one-hot encoding để đưa các nhãn về dạng vector sẽ xảy ra một số vấn đề khi có nhiều nhãn cần phân loại. Ví dụ, dự đoán các từ trong một bộ ngữ liệu có thể có hàng chục hoặc hàng trăm nghìn từ vựng khác nhau, mỗi loại tương ứng với một nhãn. Điều này có nghĩa là giá trị đích y của mỗi điểm dữ liệu huấn luyện có thể là một one-hot vectơ với hàng chục hoặc hàng trăm nghìn số 0, lúc này sẽ khá tốn bộ nhớ.
Sparse cross-entropy giải quyết vấn đề này bằng cách thực hiện cùng một phép tính toán độ lỗi của cross-entropy mà không yêu cầu biến đích y phải được đưa về dạng one-hot trước khi huấn luyện. Cross-entropy được cung cấp trong Keras bằng cách thiết lập tham số loss=‘sparse_categorical_crossentropy‘ khi compile mô hình.
1
model.compile(loss='sparse_categorical_crossentropy', optimizer=opt, metrics=['accuracy'])
Hàm yêu cầu layer đầu ra được gồm n node tương ứng với số class và sử dụng kích hoạt ‘softmax’ để dự đoán xác suất cho đầu ra cho mỗi lớp.
1
model.add(Dense(3, activation='softmax'))
Lợi ích khi sử dụng hàm mất mát sparse cross-entropy đó là không cần phải thực hiện one-hot encoding.
Code đầy đủ sử dụng hàm loss sparse cross-entropy được trình bày dưới đây:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# mlp for the blobs multi-class classification problem with sparse cross-entropy loss
from sklearn.datasets import make_blobs
from keras.layers import Dense
from keras.models import Sequential
from keras.optimizers import SGD
from matplotlib import pyplot
# generate 2d classification dataset
X, y = make_blobs(n_samples=1000, centers=3, n_features=2, cluster_std=2, random_state=2)
# split into train and test
n_train = 500
trainX, testX = X[:n_train, :], X[n_train:, :]
trainy, testy = y[:n_train], y[n_train:]
# define model
model = Sequential()
model.add(Dense(50, input_dim=2, activation='relu', kernel_initializer='he_uniform'))
model.add(Dense(3, activation='softmax'))
# compile model
opt = SGD(lr=0.01, momentum=0.9)
model.compile(loss='sparse_categorical_crossentropy', optimizer=opt, metrics=['accuracy'])
# fit model
history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=100, verbose=0)
# evaluate the model
_, train_acc = model.evaluate(trainX, trainy, verbose=0)
_, test_acc = model.evaluate(testX, testy, verbose=0)
print('Train: %.3f, Test: %.3f' % (train_acc, test_acc))
# plot loss during training
pyplot.subplot(211)
pyplot.title('Loss')
pyplot.plot(history.history['loss'], label='train')
pyplot.plot(history.history['val_loss'], label='test')
pyplot.legend()
# plot accuracy during training
pyplot.subplot(212)
pyplot.title('Accuracy')
pyplot.plot(history.history['accuracy'], label='train')
pyplot.plot(history.history['val_accuracy'], label='test')
pyplot.legend()
pyplot.show()
Sau khi chạy, kết quả sẽ in ra độ chính xác trên tập train và tập test
Chú ý khi chạy, kết quả có thể khác nhau do thuật toán khởi tạo ngẫu nhiên. Chúng ta nên chạy nhiều lần và lấy giá trị trung bình
Trong trường hợp này chúng ta có thể thấy mô hình đạt độ chính xác 83% trên tập dữ liệu huấn luyện và 81% trên tập test. Kết quả độ chính xác trên tập test và tập train khá gần nhau chứng tỏ mô hình không bị underfit hay overfit. Trên thực tế, nếu bạn lặp lại thử nghiệm nhiều lần, độ chính xác trung bình của cross-entropy và sparse cross-entropy sẽ có thể so sánh được.
Kết quả in ra sẽ là:
1
Train: 0.832, Test: 0.818
Biểu đồ đường thể hiện độ chính xác và giá trị mất mát trong quá trình huấn luyện của tập train (màu xanh) và tập test (màu cam)
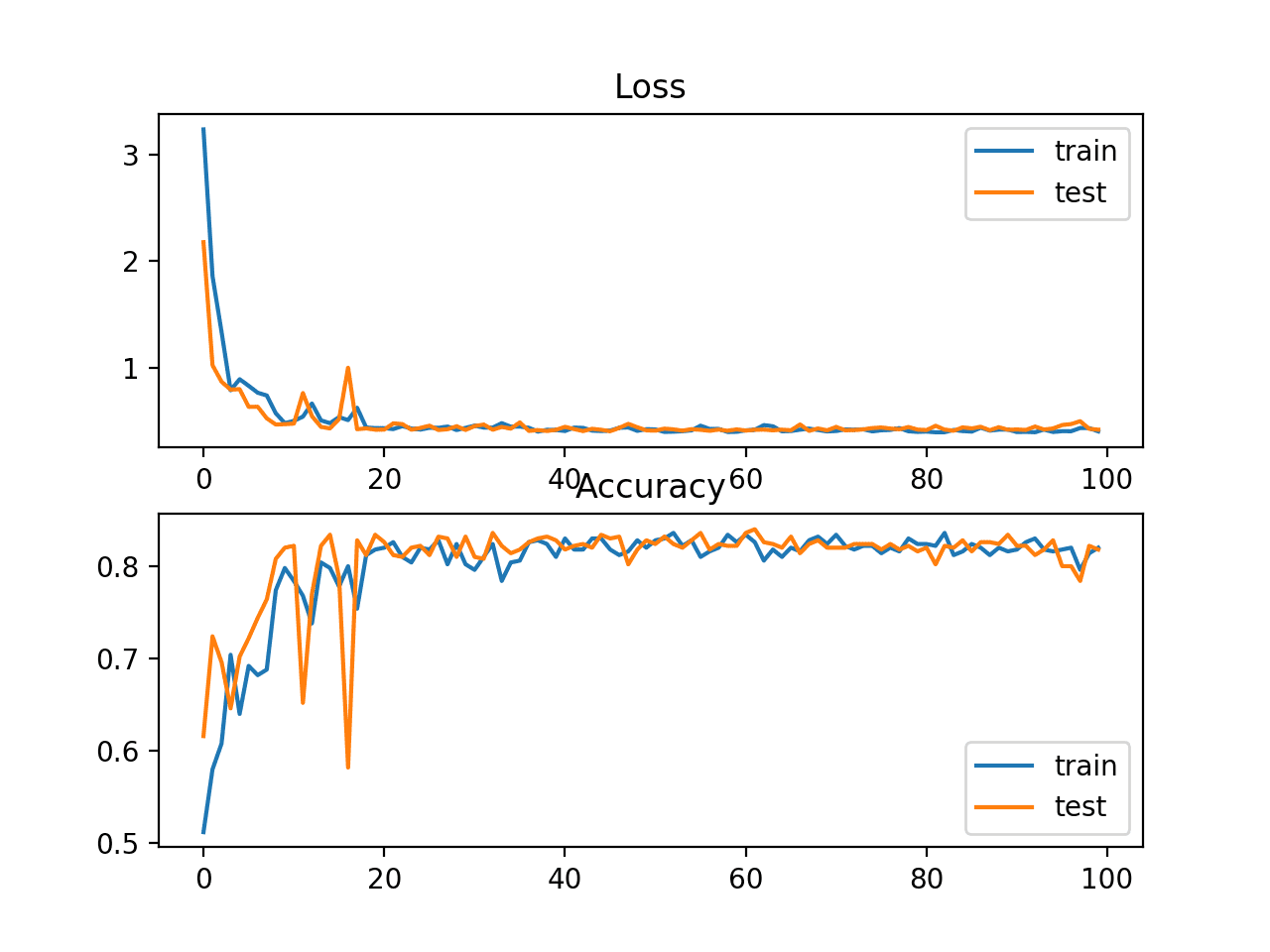 Sparse Cross-entropy và Classification Accuracy
Sparse Cross-entropy và Classification Accuracy
Tổng kết
Như vậy mình đã kết thúc 3 phần bàn về hàm loss, qua 3 phần mình đã giới thiệu cho các bạn các hàm loss hay sử dụng trong các bài toán hay gặp. Ngoài ra còn nhiều hàm loss khác mình chưa có điều kiện để giới thiệu ở đây, hẹn gặp mọi người ở các bài viết sau.
Tham khảo
Posts
- Soft Margin Support Vector Machine.
- Loss and Loss Functions for Training Deep Learning Neural Networks
Papers
API
- Keras Loss Functions API
- Keras Activation Functions API
- sklearn.preprocessing.StandardScaler API
- sklearn.datasets.make_regression API
- sklearn.datasets.make_circles API
- sklearn.datasets.make_blobs API