
Trong tìm kiếm thông tin, để xếp hạng các văn bản phù hợp với truy vấn của người dùng, người ta thường sử dụng thuật toán Okapi BM25. Thuật toán này dựa trên mô hình xác suất , được phát minh ra vào những năm 1970 – 1980. Phương pháp có tên BM25 (BM – best match), nhưng người ta thường gọi “Okapi BM25”, vì lần đầu tiên công thức được sử dụng trong hệ thống tìm kiếm Okapi, được sáng lập tại trường đại học London những năm 1980 và 1990.
BM25 là một phương pháp xếp hạng được sử dụng rộng rãi trong tìm kiếm. Trong Web search những hàm xếp hạng này thường được sử dụng như một phần của các phương pháp tích hợp để dùng trong machine learning, xếp hạng.
Một trong những kỹ thuật tìm kiếm nỗi tiếng hiện nay đang sử dụng thuật toán này là Elasticsearch. Khi tìm kiếm, Elascticsearch trả về cho mình ngoài các kết quả tìm được, còn có đánh giá độ liên quan của kết quả dựa trên giá trị thực dương score. Elasticsearch sẽ sắp xếp các kết quả trả về của các query theo thứ tự score giảm dần. Đây là điểm mà mình thấy rất thú vị trong Elasticsearch, và mình sẽ dành bài viết này để nói về cách làm thế nào người ta tính toán và đưa ra được giá trị score và từ đó hiểu được thuật toán BM25.
Một số khái niệm
-
Thuật ngữ (term): Dùng để chỉ thành phần của một truy vấn, ví dụ ta có truy vấn: “Thủ đô của Hà Nội là gì”, thuật ngữ của truy vấn sẽ là: ‘Thủ đô’, ‘của’, ‘Hà Nội’. Hiểu đơn giản, thuật ngữ là các từ trong truy vấn/văn bản mang ý nghĩa.
-
Tài liệu: Các văn bản thông thường cần tìm kiếm, truy vấn cũng có thể coi là tài liệu.
-
Tần suất thuật ngữ hay còn gọi là tf: tần suất thuật ngữ xuất hiện trong tài liệu? 3 lần? 10 lần?
-
Tần suất tài liệu nghịch đảo hay còn gọi là idf: được tính bằng số lượng tài liệu mà thuật ngữ xuất hiện. Tần suất tài liệu nghịch đảo (1 / df) cho biết mức độ quan trọng của thuật ngữ. Thuật ngữ có phải là một từ hiếm (chỉ xảy ra trong một tài liệu) hay không? Hay thuật ngữ này phổ biến (xảy ra trong gần như tất cả các tài liệu)?
Sử dụng hai yếu tố này, TFIDF cho biết độ tương đối của một thuật ngữ trong một tài liệu nào đó.
Nếu một thuật ngữ phổ biến trong tài liệu này, nhưng hiếm ở tài liệu khác, thì điểm TFIDF sẽ cao và tài liệu có điểm TFIDF cao hơn sẽ được coi là phù hợp với cụm từ tìm kiếm.
BM25 cải thiện dựa trên TFIDF bằng cách sử dụng mức độ liên quan với một bài toán xác suất. BM25 sẽ đưa ra điểm liên quan, để xác định xem một truy vấn có mức độ liên quan thế nào đến các tài liệu. Sau đó xếp hạng các điểm liên quan đó để đưa ra kết quả các tài liệu phù hợp với truy vấn.
Công thức tính BM25
Để xác định mức độ liên quan giữa một truy vấn (tài liệu) với một tài liệu khác, chúng ta có thể sử dụng công thức tính BM25 như sau:
\[\begin{align}\mbox{BM25}(D, Q) = \sum_{i=1}^n IDF(q_i, D) \frac{f(q_i, D) \cdot (k_1 + 1)}{f(q_i) + k_1 \cdot (1-b + b \cdot |D|/d_{avg}))}\end{align}\]Trong đó:
-
$f(q_i, D)$ Là số lần mà term $q_i$ xuất hiện trong tất cả các tài liệu $D$
-
$|D|$ là số từ trong tất cả các tài liệu $D$
-
$d_{avg}$ là số lượng từ trung bình trong mỗi tài liệu
-
$b$ và $k1$ là các tham số của BM25
-
$f(q_i, D)$ cho ta thấy rằng nếu một từ xuất hiện trong tài liệu càng nhiều thì điểm của tài liệu càng cao.
Phần thú vị đó là tham số k1, xác định tính bão hòa tần suất. Giá trị càng cao, độ bão hòa càng chậm. Nghĩa là nếu một từ xuất hiện nhiều sẽ làm điểm của tài liệu cao, nhưng sẽ nhiều với một mức độ nào đó và mức độ ảnh hưởng tới điểm sẽ giảm dần.
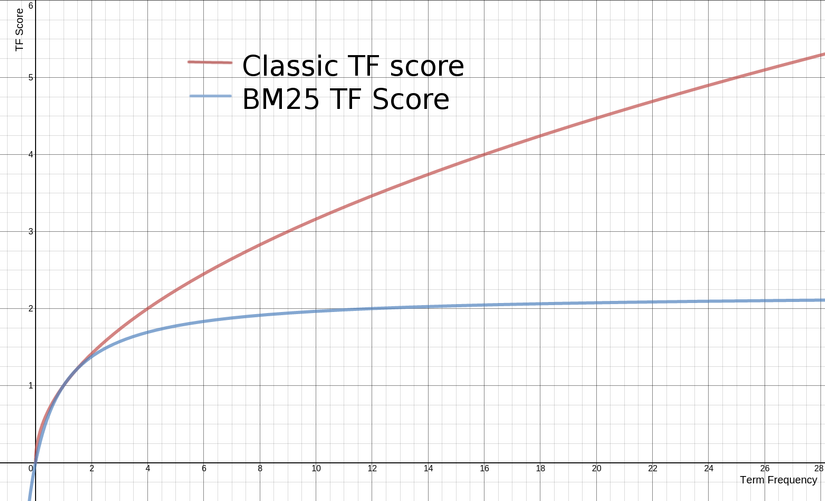 Sự ảnh hưởng của TF tới Score
Sự ảnh hưởng của TF tới Score
$|D|/d_{avg}$ ở mẫu số có nghĩa là tài liệu dài hơn các tài liệu trung bình sẽ dẫn đến mẫu số lớn hơn, dẫn đến giảm điểm. Thực tế cho ta thấy là nếu càng nhiều thuật ngữ trong tài liệu mà không khớp với truy vấn đầu vào thì điểm của tài liệu càng thấp. Nói cách khác, nếu một tài liệu dài 300 trang đề cập đến cụm từ truy vấn một lần, thì nó ít có khả năng liên quan đến truy vấn hơn so với một tài liệu ngắn đề cập đến truy vấn một lần.
Đối với phần tần suất tài liệu nghịch đảo, ${IDF}(q_i, D)$. Với tập ngữ liệu gồm N tài liệu, IDF cho thuật ngữ $q_i$ được tính như sau:
\[\begin{align} \mbox{IDF}(q_i, D) = \log \frac{N - N(q_i) + 0.5}{N(q_i) + 0.5} \end{align}\]Với
$N(q_i)$ là số lượng các tài liệu trong ngữ liệu chứa $q_i$.Phần tần suất tài liệu nghịch đảo giống với TFIDF, có vai trò đảm bảo các từ hiếm hơn sẽ có điểm cao hơn và đóng góp nhiều hơn vào điểm xếp hạng.
Lưu ý rằng công thức IDF ở trên có một nhược điểm khi sử dụng nó cho các cụm từ xuất hiện trong hơn một nửa kho ngữ liệu IDF sẽ là giá trị âm, dẫn đến điểm xếp hạng trở thành số âm. ví dụ. nếu chúng ta có 10 tài liệu trong kho ngữ liệu và thuật ngữ “là” xuất hiện trong 6 tài liệu đó, IDF của nó sẽ là log (10 - 6 + 0.5 / 6 + 0.5) = log (4.5 / 6.5). Mặc dù trong quá trình tiền xử lý chúng ta đã loại bỏ các stop-words(từ dừng) vì các từ này ít mang ý nghĩa trong câu, tuy nhiên ta vẫn cần phải tính đến trường hợp này.
Thêm 1 vào biểu thức:
\[\begin{align} \mbox{IDF}(q_i) = \log \big( 1 + \frac{N - N(q_i) + 0.5}{N(q_i) + 0.5} \big) \end{align}\]Đối với cụm từ dẫn đến giá trị IDF âm, hãy hoán đổi nó với một giá trị dương nhỏ, thường được ký hiệu là $epsilon$
Triển khai code với python
Sau khi đã có các công thức tính, ta sẽ áp dụng bài toán này vào tìm kiếm đối với tiếng Việt.
Tiền xử lý
Trong bài này mình sử dụng thư viện pyvi để thực hiện tách từ tiếng việt. Tách từ là một bước cực kỳ quan trọng trong xử lý các bài toán tiếng Việt.
Để cài đặt bạn hãy chạy pip install pyvi
Import thư viện:
1
2
3
4
5
from pyvi.ViTokenizer import tokenize
import re, os, string
import pandas as pd
import math
import numpy as np
Xóa bỏ các ký tự thừa trong text
1
2
3
4
def clean_text(text):
text = re.sub('<.*?>', '', text).strip()
text = re.sub('(\s)+', r'\1', text)
return text
Chuẩn hóa văn bản, xóa bỏ các ký tự _ và chuyển sang chữ thường
1
2
3
4
5
def normalize_text(text):
listpunctuation = string.punctuation.replace('_', '')
for i in listpunctuation:
text = text.replace(i, ' ')
return text.lower()
Loại bỏ các stop-words:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# list stopwords
filename = '../input/stopword/stopwords.csv'
data = pd.read_csv(filename, sep="\t", encoding='utf-8')
list_stopwords = data['stopwords']
def remove_stopword(text):
pre_text = []
words = text.split()
for word in words:
if word not in list_stopwords:
pre_text.append(word)
text2 = ' '.join(pre_text)
return text2
Thực hiện tách từ
1
2
3
def word_segment(sent):
sent = tokenize(sent.encode('utf-8').decode('utf-8'))
return sent
Định nghĩa mô hình
Chúng ta sẽ xây dựng mô hình BM25 như sau:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
class BM25:
def __init__(self, k1=1.5, b=0.75):
self.b = b
self.k1 = k1
def fit(self, corpus):
"""
Fit the various statistics that are required to calculate BM25 ranking
score using the corpus given.
Parameters
----------
corpus : list[list[str]]
Each element in the list represents a document, and each document
is a list of the terms.
Returns
-------
self
"""
tf = []
df = {}
idf = {}
doc_len = []
corpus_size = 0
for document in corpus:
corpus_size += 1
doc_len.append(len(document))
# compute tf (term frequency) per document
frequencies = {}
for term in document:
term_count = frequencies.get(term, 0) + 1
frequencies[term] = term_count
tf.append(frequencies)
# compute df (document frequency) per term
for term, _ in frequencies.items():
df_count = df.get(term, 0) + 1
df[term] = df_count
for term, freq in df.items():
idf[term] = math.log(1 + (corpus_size - freq + 0.5) / (freq + 0.5))
self.tf_ = tf
self.df_ = df
self.idf_ = idf
self.doc_len_ = doc_len
self.corpus_ = corpus
self.corpus_size_ = corpus_size
self.avg_doc_len_ = sum(doc_len) / corpus_size
return self
def search(self, query):
scores = [self._score(query, index) for index in range(self.corpus_size_)]
return scores
def _score(self, query, index):
score = 0.0
doc_len = self.doc_len_[index]
frequencies = self.tf_[index]
for term in query:
if term not in frequencies:
continue
freq = frequencies[term]
numerator = self.idf_[term] * freq * (self.k1 + 1)
denominator = freq + self.k1 * (1 - self.b + self.b * doc_len / self.avg_doc_len_)
score += (numerator / denominator)
return score
Tham số mô hình
-
k1 : float, mặc định là 1.5
-
b : float, mặc định là 0.75
Các thuộc tính
-
tf_ : list[dict[str, int]] Số lần xuất hiện của từ trong tài liệu. Ví dụ [{‘đẹp’: 1}] nghĩa là tài liệu đầu tiên chứa thuật ngữ ‘đẹp’ 1 lần.
-
df_ : dict[str, int] Số tài liệu trong tập ngữ liệu chứa thuật ngữ
-
idf_ : dict[str, float] IDF của thuật ngữ.
-
doc_len_ : list[int] Số thuật ngữ (từ) trong mỗi tài liệu. Ví dụ [3] Nghĩa là tài liệu chứa 3 thuật ngữ (từ).
-
corpus_ : list[list[str]] Tập ngữ liệu đầu vào
-
corpus_size_ : int Số lượng tài liệu trong bộ ngữ liệu
-
avg_doc_len_ : float Giá trị trung bình các thuật ngữ trong một tài liệu của ngữ liệu
Chuẩn bị dữ liệu
Trong bài viết này mình sẽ dùng bộ dữ liệu demo của wikipedia tiếng việt, các bạn có thể download tại:
https://drive.google.com/file/d/1Uuj3s2Zr5ZQ9KHk6fWsQJ-AUwKkhjvPe/view?usp=sharing
Sau khi download, các bạn giải nén ra máy tính.
Ngoài ra mình cũng sử dụng danh sách stop-word của một bài viết trên viblo:
https://drive.google.com/file/d/1E0vtC2tPPKE5bWbFP3A3J7zfCVwHNg2M/view?usp=sharing
Tiến hành đọc dữ liệu từ tập ngữ liệu:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
path_to_corpus = '../input/demo-wiki'
def get_docs(docs_dir):
docs = []
# f_w = open('./datatrain.txt', 'w')
for i, sub_dir in enumerate(os.listdir(path_to_corpus)):
path_to_subdir = path_to_corpus + '/' + sub_dir
print(path_to_subdir)
if os.path.isdir(path_to_subdir):
for j, file_name in enumerate(os.listdir(path_to_subdir)):
print(file_name)
with open(path_to_subdir + '/' + file_name) as f_r:
contents = f_r.read().strip().split('</doc>')
for content in contents:
if (len(content) < 5):
continue
content = clean_text(content)
content = word_segment(content)
content = remove_stopword(normalize_text(content))
docs.append(content)
return docs
1
2
3
4
5
6
docs = get_docs(path_to_corpus)
texts = [
[word for word in document.lower().split() if word not in list_stopwords]
for document in docs
]
Huấn luyện mô hình
Trong phần này chúng ta chỉ cần đưa danh sách các tài liệu (mỗi tài liệu là một vector các từ) vào trong hàm fit() của mô hình BM25.
1
2
bm25 = BM25()
bm25.fit(texts)
Thực hiện tìm kiếm
Chúng ta sẽ xếp hạng các tài liệu dựa trên score, tài liệu nào có điểm cao hơn sẽ có thứ hạng cao hơn:
1
2
3
4
5
6
7
8
9
10
11
12
13
limit = 10
query = 'Hội đồng nhân dân'
query = clean_text(query)
query = word_segment(query)
query = remove_stopword(normalize_text(query))
query = query.split()
scores = bm25.search(query)
scores_index = np.argsort(scores)
scores_index = scores_index[::-1]
print(np.array([docs[i] for i in scores_index])[:limit])
Kết quả tìm kiếm
1
2
3
4
5
6
7
8
[ 0 71 70 69 68 67 66 64 63 62 72 61 59 58 57 56 109 54
52 51 50 60 74 76 77 108 107 106 105 104 103 101 99 98 96 95
94 93 91 86 85 84 82 81 80 79 49 48 55 46 24 23 19 18
17 16 15 14 13 12 11 10 9 8 5 3 2 25 28 21 110 36
35 38 33 32 37 40 39 43 31 44 30 45 41 29 92 65 20 90
83 6 26 78 47 7 87 27 4 75 42 89 73 1 102 53 22 88
34 97 100]
['chính_quyền địa_phương ở việt_nam chính_quyền địa_phương ở việt_nam bao_gồm ủy_ban nhân_dân hành_pháp hội_đồng nhân_dân lập_pháp ở ba cấp xã huyện và tỉnh và tòa_án nhân_dân tư_pháp ở hai cấp huyện và tỉnh khác với chế_độ liên_bang federation của một_số nước chính_quyền địa_phương của việt_nam là một bộ_phận hợp_thành của chế_độ đơn_nhất unitary state chính_quyền địa_phương việt_nam bao_gồm khái_niệm chính_quyền địa_phương là khái_niệm phát_sinh từ khái_niệm hệ_thống các cơ_quan nhà_nước ở địa_phương khái_niệm này được sử_dụng khá phổ_biến trong nhiều văn_bản pháp_luật của nhà_nước là một khái_niệm được sử_dụng nhiều trong tổ_chức và hoạt_động của nhà_nước vào đời_sống thực_tế xã_hội tuy_nhiên hiện_nay vẫn chưa có một văn_bản pháp_luật nào định_nghĩa khái_niệm chính_quyền địa_phương bao_gồm những thiết chế nào mối quan_hệ và cơ_chế hoạt_động cụ_thể của các bộ_phận cấu_thành xuất_phát từ góc_độ nghiên_cứu lý_luận từ góc_độ thực_tiễn hay cách_thức tiếp_cận v...]