
Bài trước mình đã giới thiệu mọi người cách để huấn luyện mô hình học máy, trong đó mục đích của việc huấn luyện là để tìm ra các tham số mà tại đó hàm chi phí (hàm mất mát) đạt giá trị nhỏ nhất.
Trong toán tối ưu, việc tìm ra cực trị của hàm số rất phổ biến. Có nhiều phương pháp để tìm cực trị hàm số, trong đó cách phổ biến nhất là tìm đạo hàm rồi giải phương trình đạo hàm bằng 0, các nghiệm sẽ là hữu hạn và thay từng nghiệm vào hàm số ta sẽ được các giá trị cực tiểu, sau đó lấy nghiệm làm cho hàm số có giá trị nhỏ nhất.
Tuy nhiên thì không phải lúc nào chúng ta cũng có thể tìm ra được đạo hàm cũng như giải phương trình đạo hàm. Lý do là do hàm số có đạo hàm phức tạp, dữ liệu có nhiều chiều… Vì vậy người ta nghĩ ra 1 cách để tìm cực trị (cực tiểu/cực đại) bằng phương pháp Gradient Descent.
Gradient Descent là gì?
Gradient Descent (GD) là thuật toán tìm tối ưu chung cho các hàm số. Ý tưởng chung của GD là điều chỉnh các tham số để lặp đi lặp lại thông qua mỗi dữ liệu huấn luyện để giảm thiểu hàm chi phí.
Giả sử bạn bị lạc trên 1 ngọn núi và trong sương mù dày đặc, bạn chỉ có thể cảm thấy độ dốc của mặt đất dưới chân bạn. Một cách tốt nhất để nhanh chóng xuống chân núi là xuống dốc theo hướng dốc nhất. Đây chính là ý tưởng của Gradient Descent thực hiện, tại mỗi điểm của hàm số, nó sẽ xác định độ dốc sau đó đi ngược lại với hướng của độ dốc đến khi nào độ dốc tại chỗ đó bằng 0 (cực tiểu)
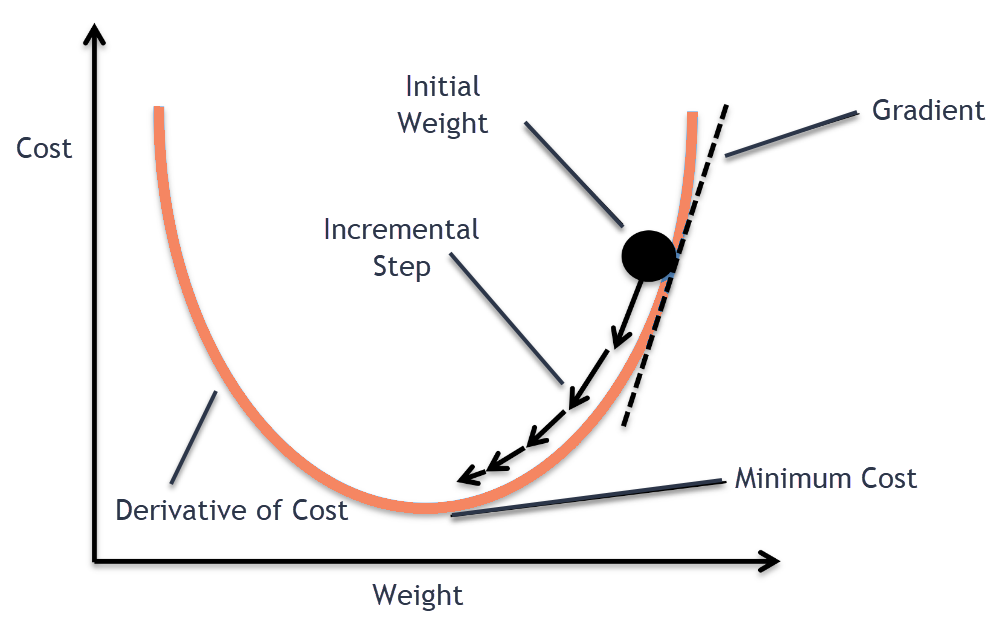 Mô phỏng thuật toán Gradient Descent
Mô phỏng thuật toán Gradient Descent
Gradient Descent là một thuật toán tối ưu lặp (iterative optimization algorithm) được sử dụng trong các bài toán Machine Learning và Deep Learning (thường là các bài toán tối ưu lồi — Convex Optimization) với mục tiêu là tìm một tập các biến nội tại (internal parameters) cho việc tối ưu models. Trong đó:
- Gradient: là tỷ lệ độ nghiêng của đường dốc (rate of inclination or declination of a slope). Về mặt toán học, Gradient của một hàm số là đạo hàm của hàm số đó tương ứng với mỗi biến của hàm. Đối với hàm số đơn biến, chúng ta sử dụng khái niệm Derivative thay cho Gradient.
- Descent: là từ viết tắt của descending, nghĩa là giảm dần.
Gradient Descent có nhiều dạng khác nhau như Stochastic Gradient Descent (SGD), Mini-batch SDG. Nhưng về cơ bản thì đều được thực thi như sau:
- Khởi tạo biến nội tại.
- Đánh giá model dựa vào biến nội tại và hàm mất mát (Loss function).
- Cập nhật các biến nội tại theo hướng tối ưu hàm mất mát (finding optimal points).
- Lặp lại bước 2, 3 cho tới khi thỏa điều kiện dừng.
- Công thức cập nhật cho GD có thể được viết là:
trong đó $θ$ là tập các biến cần cập nhật, $η$ là tốc độ học (learning rate), $▽Өf(θ)$ là Gradient của hàm mất mát f theo tập θ.
Learning rate
Có 1 tham số quan trọng trong Gradient Descent đó là giá trị độ lớn của mỗi lần di chuyển (giống như độ dài sải chân khi bạn leo xuống dốc).
Tham số này được gọi là learning rate (tốc độ học). Nếu learning rate quá nhỏ, thuật toán sẽ phải thực hiện nhiều bước để hội tụ và sẽ mất nhiều thời gian.
Tuy nhiên nếu learning rate quá lớn sẽ khiến thuật toán đi qua cực tiểu, và vượt hẳn ra ngoài khiến thuật toán không thể hội tụ được.
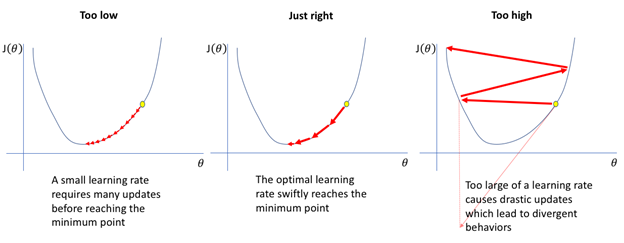 Sự ảnh hưởng của learning rate đến mô hình
Sự ảnh hưởng của learning rate đến mô hình
Trong thực tế, không phải hàm số nào cũng chỉ có 1 cực tiểu. Ta sẽ có khái niệm cực tiểu cục bộ và cực tiểu toàn cục. Hiểu nôm na nó giống như các hố hoặc các tảng đá ở trên núi khi bạn đang leo xuống núi. Lúc này việc tìm ra cực tiểu sẽ trở nên khó khăn hơn. Xem hình sau để biết chi tiết:
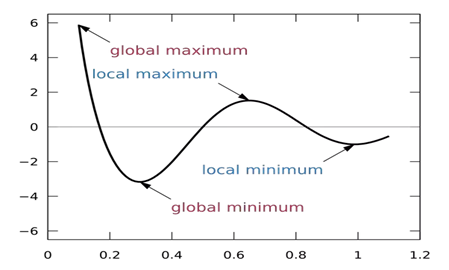 Cực trị hàm số
Cực trị hàm số
Sẽ có 2 vấn đề lúc này đối với GD:
Điểm xuất phát có thể ở bên trái hoặc bên phải, nếu xuất phát từ bên trái, thuật toán sẽ hội tụ ở local minimum (cực tiểu địa phương) mà không đi đến được global minium (cực tiểu toàn cục).
Hoặc nếu xuất phát từ bên phải sẽ phải mất nhiều thời gian để vượt qua Plateau để đến được global minimum và nếu kết thúc thuật toán quá sớm thì sẽ không đến được global minimum.
Bài trước chúng ta có sử dụng hàm chi phí MSE cho bài toán hồi quy tuyến tính, rất may là hàm này là hàm lồi. Nghĩa là nếu 1 đường thẳng nối 2 điểm bất kì trên đồ thị hàm lồi thì đường thẳng này sẽ không cắt đồ thị. Điều này nghĩa là không có cực tiểu địa phương (local minimum) mà chỉ có 1 cực tiểu toàn cục. Đây cũng là một hàm liên tục có độ dốc không bao giờ thay đổi đột ngột. Vì vậy ỏ đây GD có 1 vấn đề, đó là nó sẽ không tiến gần đến được global minimum (trừ khi thời gian học đủ lâu và learning rate đủ nhỏ)
Trên thực tế, hàm chi phí có dạng đồ thị giống chiếc bát, nếu các feature (đặc điểm của đầu vào - thành phần của vector X) có cùng phạm vi giá trị, thì miệng bát sẽ tròn và để GD đi xuống đáy bát sẽ nhanh hơn. Nếu các feature khác phạm vi giá trị thì miệng bát sẽ bị kéo dài ra và việc đi xuống đáy bát sẽ tốn thời gian hơn. Đây là lý do vì sao các feature của vector đầu vào X cần phải được scaling (căn chỉnh).
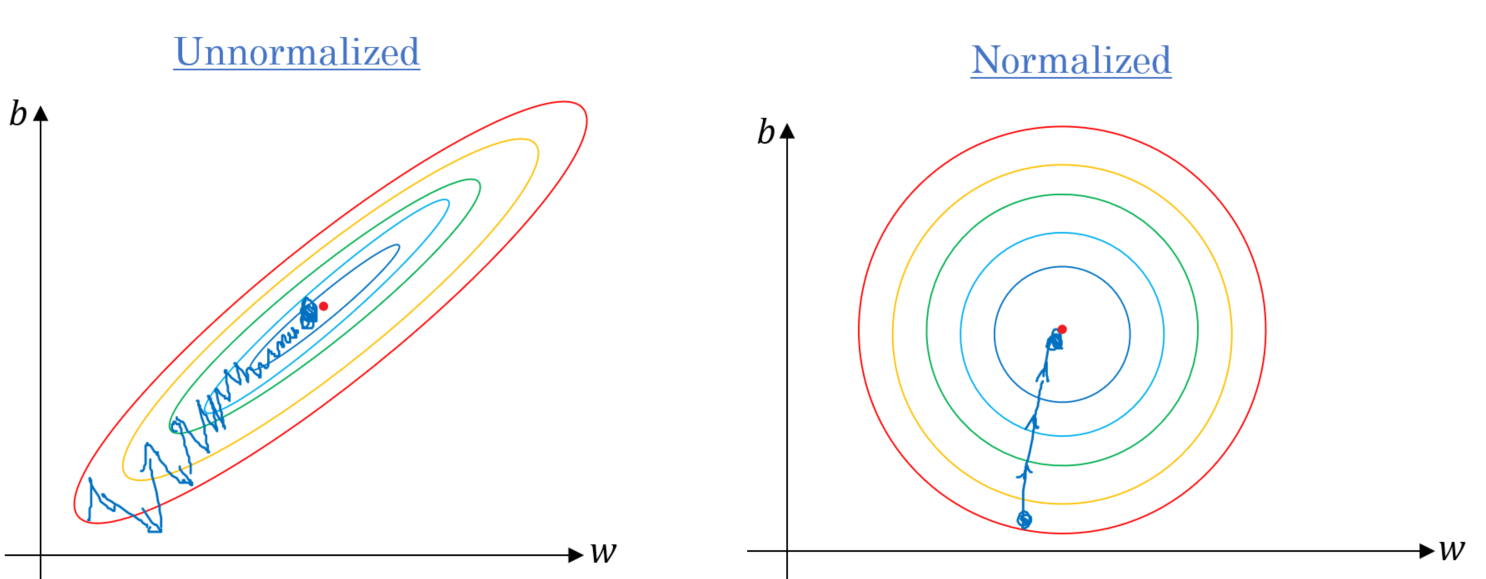 GD có scaling và không scaling
GD có scaling và không scaling
Như bạn có thể thấy, ở bên phải thuật toán Gradient Descent đi thẳng về điểm tối thiểu, do đó nhanh chóng đạt được cực tiểu toàn cục, trong khi bên trái, nó đi theo hướng gần như trực giao với hướng về cực thiểu toàn cục, vì vậy nó kết thúc bằng 1 hành trình dài xuống một 1 mặt gần như bằng phẳng. Cuối cùng nó sẽ đạt đến mức cực tiểu, nhưng sẽ mất nhiều thời gian.
Khi bạn thực hiện thuật toán Gradient Descent, bạn nên đưa các feature về cùng phạm vi giá trị (sử dụng StandardScaler của thư viện Scikit-Learn
Batch Gradient Descent
Để thực hiện thuật toán Gradient Descent, chúng ta phải tìm được đạo hàm của hàm chi phí ảnh hưởng đến từng tham số của mô hình $ \theta_j $. Nói khác đi, cần phải xác định được giá trị hàm chi phí thay đổi thế nào nếu thay đổi $ \theta_j $. Cái này được gọi là đạo hàm riêng (partial derivative).
Biểu thức sau sẽ dùng để tính đạo hàm riêng của hàm chi phí cho tham số $ \theta_j $, được ký hiệu là $ \frac{\delta}{\delta\theta_j}MSE(\theta) $:
\[\frac{\delta}{\delta\theta_j}MSE(\theta) = \frac{2}{m}\sum_{i=1}^m(\theta^Tx^{(i)} - y^{(i)})x^{(i)}_j\]Thay vì tính từng đạo hàm thành phần, bạn có thể sử dụng công thức sau để tính tất cả trong 1 bước. Vector độ dốc, ký hiệu $ ∇_\theta MSE(\theta) $ là đạo hàm riêng (vector độ dốc) cho các tham số $ \theta) $ của mô hình.
Khi chúng ta có vector độc dốc và vị trí hiện tại, chúng ta chỉ cần đi ngược lại với vector độ dốc. Nghĩa là ta phải trừ θ đi 1 giá trị là $ ∇_\theta MSE(\theta) $. Lúc này ta sẽ sử dụng tham số learning rate $ \eta $ để xác định giá trị của bước xuống dốc bằng cách nhân vào.
\[\theta^{(next step)} =\theta - \eta ∇_\theta MSE(\theta)\]Bây giờ chúng ta sẽ thực hiện thử bài trước bằng Python:
1
2
3
4
5
eta = 0.1 # learning rate n_iterations = 1000 m=100
theta = np.random.randn(2,1) # random initialization
for iteration in range(n_iterations):
gradients = 2/m * X_b.T.dot(X_b.dot(theta) - y)
theta = theta - eta * gradients
Kết quả của theta sẽ như sau:
1
2
3
>>> theta
array([[4.21509616],
[2.77011339]])
Như vậy là có vẻ GD hoạt động tốt. Nhưng nếu sử dụng learning rate khác nhau thì sao? Hình sau sẽ cho ta thấy 10 bước lặp của thuật toán với các learning rate khác nhau:
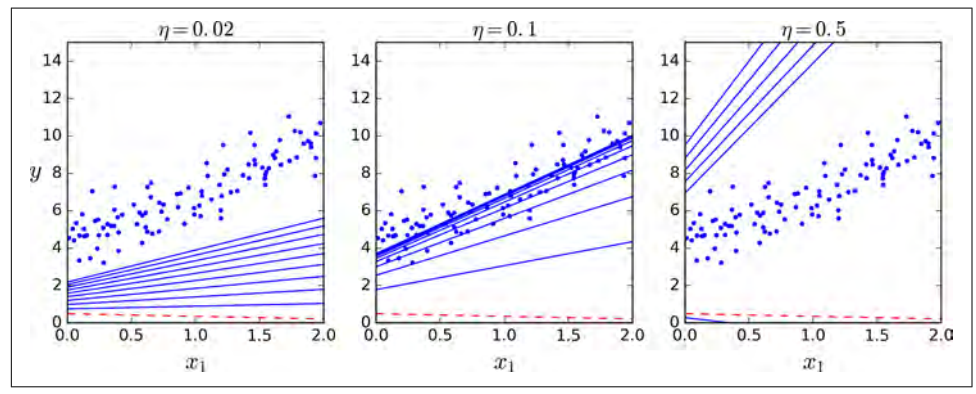 GD với các learning rate khác nhau
GD với các learning rate khác nhau
Ở bên trái, learning rate quá thấp: thuật toán cuối cùng sẽ hội tụ, nhưng sẽ mất nhiều thời gian. Ở giữa, learning rate có vẻ khá tốt: chỉ trong vài lần lặp thuật toán đã hội tụ. Ở bên phải, learning rate quá cao: thuật toán phân kỳ, nhảy khắp nơi và ngày càng rời xa cực tiểu ở mỗi bước lặp.
Ở bài sau, mình sẽ hướng dẫn bạn các để tìm learning rate phù hợp cho từng bài toán. Còn 1 vấn đề nữa đó là số lần lặp của thuật toán, nếu thực hiện ít bước lặp, thuật toán có thể không đến được cực tiểu, còn nếu nhiều quá thuật toán có thể mất nhiều thời gian thực hiện mà các tham số hầu như không thay đổi do đã đến đích. Giải pháp đơn giản đó là ta sẽ dừng thuật toán khi giá trị chuẩn của vector độ dốc (gradient vector) đủ nhỏ và nhỏ hơn 1 số ε (được gọi là dung sai) để chắc chắn thuật toán đã đến điểm hội tụ.
Khi hàm chi phí là hàm lồi và độ dốc của nó không thay đổi đột ngột (như trường hợp của hàm MSE), Batch Gradient Descent với learning rate cố định cuối cùng sẽ hội tụ đến cực tiểu, tuy nhiên bạn có thể phải chờ một khoảng thời gian lâu hơn: nó có thể mất các bước lặp O(1 /ε) để cực tiểu trong phạm vi ε phụ thuộc vào hình dạng của hàm chi phí. Nếu bạn chia ε cho 10 để có kết quả tốt hơn thì thuật toán có thể phải chạy lâu hơn khoảng 10 lần.
Stochastic Gradient Descent
Thay vì sử dụng toàn bộ tập huấn luyện thì Stochastics Gradient Descent (SGD) sẽ lấy ngẫu nhiên 1 phần tử ở tập huấn luyện và thực hiện tính lại vector độ dốc dựa chỉ dựa trên 1 điểm dữ liệu, sau đó lặp đi lặp lại đến khi kết thúc. Và việc tính toán dựa trên 1 điểm dữ liệu sẽ khiến thuật toán chạy nhanh hơn bởi có rất ít dữ liệu cần xử lý ở mỗi vòng lặp. Và điều này cũng giúp mô hình có thể được huấn luyện với những dữ liệu lớn vì mỗi vòng lặp chỉ cần đưa 1 điểm dữ liệu vào trong bộ nhớ.
Mặt khác do tính chất ngẫu nhiên của dữ liệu đưa vào nên trong quá trình huấn luyện, thay vì hàm chi phí giảm từ từ giống Batch GD thì hàm chi phí của SGD sẽ lúc tăng lúc giảm nhưng sẽ giảm dần theo khoảng thời gian. Dần dần nghiệm của bài toán nó sẽ tiệm cận rất gần với cực tiểu nhưng khi đã đạt được cực tiểu thì giá trị hàm chi phí sẽ liên tục thay đổi mà không giữ ổn định. Khi gặp điều kiện dừng ta sẽ được bộ tham số cuối cùng đủ tốt, nhưng chưa thật sự tối ưu.
Khi hàm chi phí liên tục thay đổi có thể giúp thuật toán nhảy ra khỏi cực tiểu địa phương. Vì vậy SGD có cơ hội để tìm được cực trị toàn cục hơn là Batch Gradient Descent. Vì vậy lựa chọn ngẫu nhiên dữ liệu sẽ giúp thoát khỏi nghiệm tối ưu cục bộ nhưng điều đó nghĩa là thuật toán cũng không bao giờ có nghiệm cực tiểu.
Giảm dần learning rate
Người ta nghĩ ra thêm được 1 cách giải quyết đó là giảm dần learning rate trong quá trình huấn luyện. Các vòng lặp đầu tiên chúng ta sẽ để learning rate lớn để thoát khỏi cực tiểu địa phương, sau đó giảm dần tốc độ học để đạt được cực tiểu toàn cục. Hàm để xác định learning rate ở mỗi lần lặp được gọi là hàm lên lịch cho tốc độ học.
Nếu learning rate giảm quá nhanh, thuật toán có thể bị dừng ở điểm cực tiểu địa phương, hoặc kết thúc ở lưng chừng khi chưa đến điểm cực tiểu. Nếu learning rate giảm quá chậm, hàm chi phí có thể thay đổi lên xuống mức tối thiểu trong một thời gian dài và kết thúc bằng một nghiệm tối ưu nếu bạn dừng việc training quá sớm.
Đoạn code sau mô phỏng việc giảm dần learning rate trong quá trình training:
1
2
3
4
5
6
7
8
9
10
n_epochs = 50
t0, t1 = 5, 50 # learning schedule hyperparameters
def learning_schedule(t): returnt0/(t+t1)
theta = np.random.randn(2,1) # random initialization
for epoch in range(n_epochs):
for i in range(m):
random_index = np.random.randint(m)
xi = X_b[random_index:random_index+1]
yi = y[random_index:random_index+1] gradients = 2 *xi.T.dot(xi.dot(theta) - yi) eta = learning_schedule(epoch * m + i) theta = theta - eta * gradients
Đánh giá SGD
Thuật toán lặp đi lặp lại bởi các vòng lặp m, mỗi lần lặp lại được gọi là 1 epoc. Trong bài trước khi sử dụng Batch GD lặp lại 1000 lần thì SGD chỉ cần đến 50 lần là được kết quả khá tốt.
1
2
3
>>> theta
array([[4.21076011],
[2.74856079]])
Lưu ý với SGD
Vì việc lựa chọn các điểm dữ liệu để huấn luyện là ngẫu nhiên nên 1 vài điểm dữ liệu có thể được chọn nhiều lần ở các epoc khác nhau và 1 số điểm dữ liệu thì lại không được dùng đến. Cho nên nếu bạn muốn chắc chắn thuật toán đi qua hết các điểm dữ liệu thì cách tốt nhất là sắp xếp lại ngẫu nhiên tập huấn luyện sau mỗi epoc.
Để thực hiện Linear Regression sử dụng SGD với Scikit-Learn, bạn có thể sử dụng SGDRegressor class. Mặc định nó sẽ tối ưu bình phương hàm chi phí , đoạn code sau sẽ chạy tối đa 1000 epochs (max_iter=1000) hoặc đến khi hàm mất mát nhỏ hơn 1e-3 (tol=1e-3). Bắt đầu với learning rate = 0.1 (eta0 = 0.01). Sử dụng hàm lên lịch mặc định:
1
2
3
4
from sklearn.linear_model import SGDRegressor
sgd_reg = SGDRegressor(max_iter=1000, tol=1e-3, penalty=None, eta0=0.1) sgd_reg.fit(X, y.ravel())
#>>> sgd_reg.intercept_, sgd_reg.coef_
#(array([4.24365286]),array([2.8250878]))
Mini-batch Gradient Descent
Thuật toán Gradient Descent cuối cùng mà chúng ta nghiên cứu đó là Mini-batch Gradient Descent. Nếu chúng ta hiểu về batch GD và SGD thì sẽ dễ dàng hiểu về Mini-batch GD: ở mỗi bước, thay vì tính toán vector độ dốc dựa trên toàn bộ tập huấn luyện (như thằng Batch GD) hoặc dựa trên 1 điểm dữ liệu (như thằng Stochastic GD) thì Mini-batch GD tính gradients dựa trên 1 tập nhỏ ngẫu nhiên các điểm dữ liệu được gọi là mini- batches. Ưu điểm chính của Mini-batch GD so với Stochastic GD đó là chúng ta có thể tận dụng tối đa được hiệu suất phần cứng khi thực hiện các phép toán trên ma trận, ví dụ như GPU (tận dụng khả năng tính toán song song của phần cứng)
Mini-batch GD sẽ tiến đến gần cực tiểu toàn cục hơn SGD nhưng sẽ khó để thoát khỏi cực tiểu địa phương hơn. Dù vậy SGD và Mini-batch GD sẽ tiến đến cực tiểu toàn cục nếu chúng ta áp dụng giảm dần learning rate hợp lý.
 Mini-batch Gradient Descent
Mini-batch Gradient Descent